- 阿里云对象存储同城冗余的标准版存储单价为 0.12 元/GiB/月,相较于 ESSD PL1 的单价(1 元/1 GiB/月)便宜 8 倍以上。同时,对象存储天然具备多可用区的可用性和持久性,数据无需额外再做复制,使得相比较传统的基于云盘的 3 副本架构,成本能节省 25 倍。
- 共享存储架构相比较 Shared-Nothing 架构,是真正的存算分离,数据跟计算节点无绑定关系。因此,AutoMQ 在进行分区移动时无需复制数据,能够做到真正的秒级无损分区迁移。这也是支撑 AutoMQ 流量实时重平衡和秒级节点水平扩缩容的原子能力。
S3 存储架构
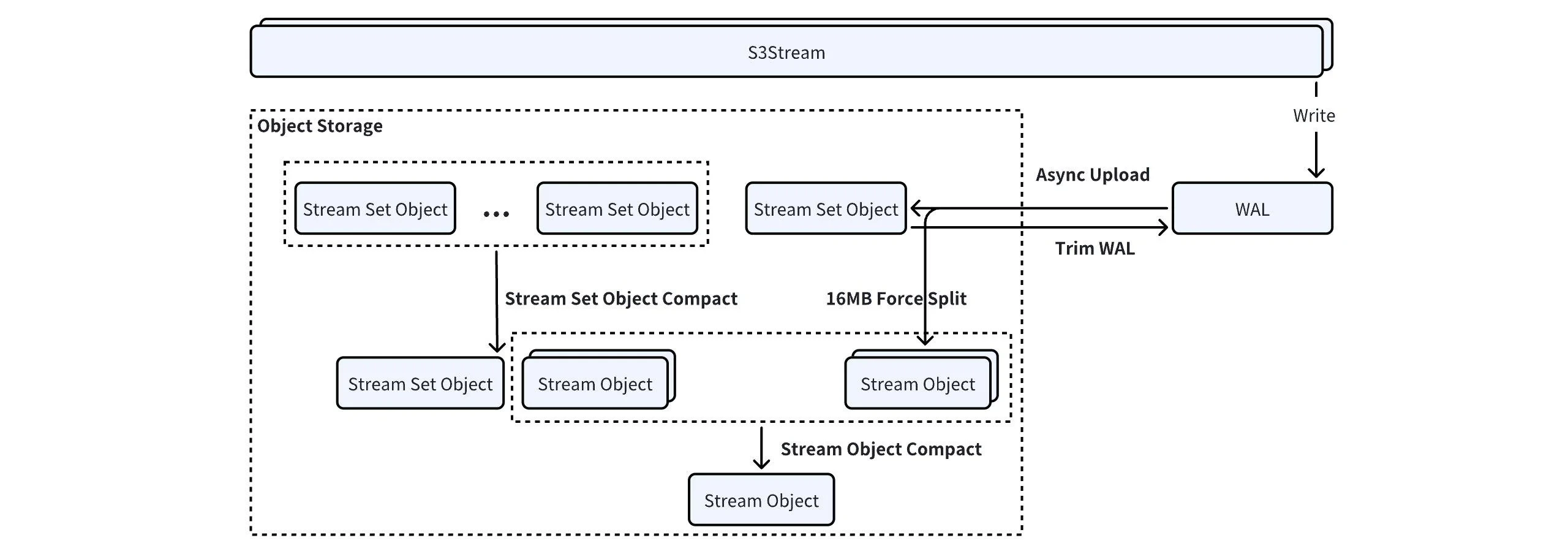
- Stream Set Object: WAL 数据上传的时候,大部分数据量较小的 Stream 会合并作为一个 Stream Set Object 上传。
- Stream Object: Stream Object 里面只有单个 Stream 的数据,方便对不同生命周期的 Stream 做精细化的数据删除。
- Metadata Stream: 元数据流保存数据索引、Kafka LeaderEpoch 快照、Producer 快照等信息。
- Data Stream: 数据流保存分区中完整的 Kafka 数据。
StreamSet Object Compact
StreamSet Object Compact 会在 Broker 后台以 20min 的间隔定期执行。类似 RocksDB SST, StreamSet Object Compact 根据策略选取当前 Broker 合适的 StreamSet Object 列表,采用归并排序合并的方式进行合并:- 对于合并后会超过 16MiB 的 Stream,会分裂出一个单独的 Stream Object 上传;
- 剩余的 Stream 归并排序写入到一个新的 StreamSet Object 中。
Stream Object Compact
Stream Object Compact 的核心目的是节省集群维护 Object 映射的元数据总量,并且提高 Stream Object 数据的聚合度以减少冷数据 Catch-up Read 的 API 调用费用。 参与到 Compact 的 Stream Object 通常已经是 16MB,满足对象存储的最小 Part 限制。Stream Object Compact 会使用对象存储的 MultiPartCopy API 来直接进行 Range Copy 上传,避免从对象存储读取再写入浪费网络带宽。多 Bucket 架构
对象存储作为各个云厂商最重要的存储服务,提供了 12 个 9 的数据持久性和高达 4 个 9 的可用性。但软件的故障永远都无法被消除,对象存储依然可能出现重大的软件故障,从而导致 AutoMQ 服务不可用。 另一方面,在云端,多云、多地域、甚至混合云的架构形态逐渐萌芽,以满足企业更灵活的 IT 治理诉求。 鉴于此,AutoMQ 企业版创新性地通过多 Bucket 架构来进一步提高系统的可用性,以及满足企业更灵活的 IT 治理诉求。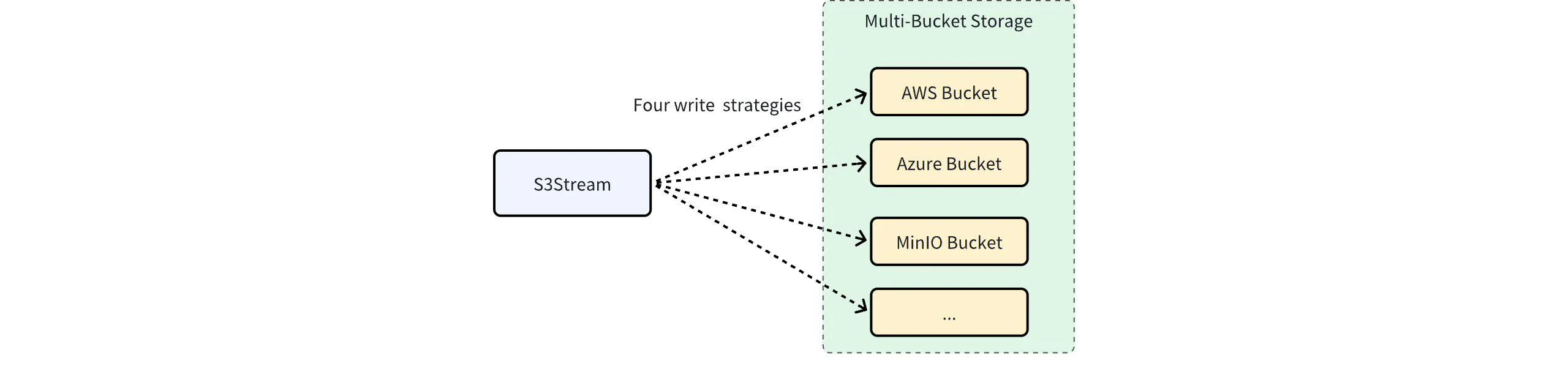
轮询法(Round Robin)
多个 Bucket 被同等对待,以轮询地方式写入。一般用于突破云厂商对单个 Bucket 或者单个账户的带宽限制。比如一个 Bucket 如果仅支持 5GiB/s 的带宽,可以通过组合两个 Bucket 来达到 10GiB/s 的带宽,以支持超大流量规模的业务场景。故障转移(Failover)
对象存储依然可能出现故障,甚至软件级故障可能比可用区级的故障更严重。对于那些对可用性要求极高的业务场景,可以通过故障转移地方式写入两个 Bucket。故障转移场景下的 Bucket 配置可能为:- 其中一个作为主 Bucket,跟业务在同地域,数据尽可能写入主 Bucket。
- 在另外一个地域,甚至另外一朵云创建一个备用 Bucket。跟主地域通过专线或者公网的形式打通网络,当主地域的对象存储不可用时,新的数据提交到备用 Bucket。备用链路会付出较高的网络成本,但因为仅发生在主 Bucket 不可用期间,成本相对可控。