S3 Storage
In the stream repository S3Stream, S3 storage serves as another core component. The Write-Ahead Log (WAL) is only used for write acceleration and fault recovery, whereas S3 is the actual data storage location. Massive amounts of data are migrating to the cloud, and object storage has become the de facto storage engine for big data and data lake ecosystems. Today, we see a plethora of data-intensive software transitioning from file APIs to object APIs, with Kafka leading the trend of streaming data into data lakes.
S3Stream leverages the Object API to efficiently read and ingest streaming data and, through a compute-storage separation architecture, connects Apache Kafka's storage layer to object storage, fully capitalizing on the technical and cost advantages of shared storage:
Alibaba Cloud's object storage standard edition with in-city redundancy is priced at 0.12 RMB/GiB/month, which is more than eight times cheaper than ESSD PL1's price (1 RMB/1 GiB/month). Additionally, object storage inherently offers multi-availability zone availability and durability, eliminating the need for extra data replication, thus saving up to 25 times the cost compared to the traditional 3-replica architecture based on cloud disks.
Compared to the Shared-Nothing architecture, the shared storage architecture achieves true compute-storage separation, with no binding relationship between data and compute nodes. Therefore, AutoMQ does not need to replicate data when reassigning partitions, enabling true second-level lossless partition reassignment. This capability underpins AutoMQ's real-time traffic self-balancing and second-level horizontal scaling of nodes.
S3 Storage Architecture
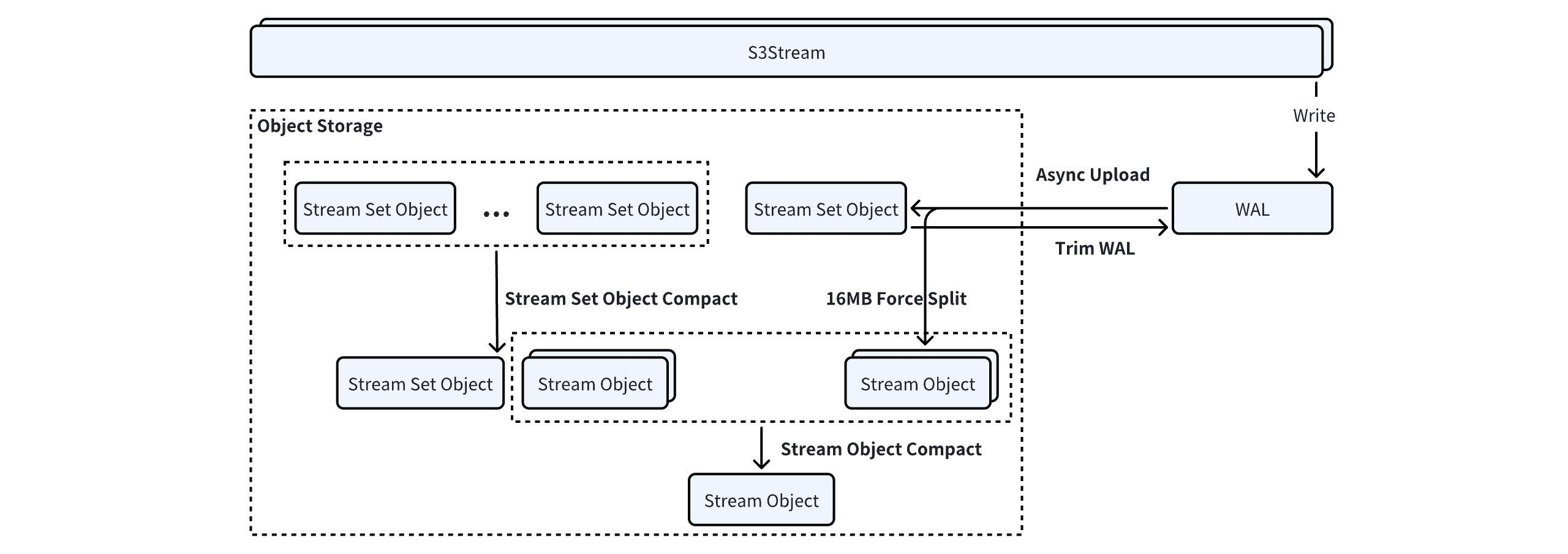
All data in AutoMQ is stored in object storage via S3Stream, which defines two object types in object storage:
Stream Set Object: When uploading WAL data, most smaller streams are merged and uploaded as a Stream Set Object.
Stream Object: A Stream Object contains data for only a single stream, allowing for granular data deletion for streams with different lifecycles.
Kafka partitions data across multiple streams, focusing on two core streams:
Metadata Stream: The Metadata Stream stores data indices, Kafka LeaderEpoch snapshots, Producer snapshots, and other information.
Data Stream: The Data Stream contains the complete Kafka data for the partition.
Metadata for objects stored on S3 is maintained in KRaft. To reduce metadata size in scenarios with massive partitions, S3Stream offers two compaction mechanisms to merge small objects and thus reduce metadata scale.
StreamSet Object Compact
StreamSet Object Compaction runs periodically in the broker's background at 20-minute intervals. Similar to RocksDB SST, StreamSet Object Compaction selects a suitable list of StreamSet Objects from the current broker according to a strategy and merges them using merge sort:
Streams that exceed 16MiB after merging are split into separate Stream Objects and uploaded individually.
Remaining streams are merge-sorted and written into a new StreamSet Object.
Merge sorting for StreamSet Object compaction, under 500MiB memory usage and 16MiB read/write range, can handle the compaction of up to 15TiB of StreamSet Objects.
Through StreamSet Object Compact, fragmented small Stream data segments are merged into larger data segments, significantly reducing API calls and enhancing read efficiency for cold data catch-up read scenarios.
Stream Object Compact
The core purpose of Stream Object Compact is to save the total metadata volume that the cluster maintains for object mapping and to increase the aggregation of Stream Object data to reduce the API call costs for cold data catch-up read.
Stream Objects participating in the compact process are typically already 16MB, meeting the minimum part size requirement for object storage. Stream Object Compact leverages the MultiPartCopy API of object storage to perform range copy uploads directly, avoiding the waste of network bandwidth that comes from reading and writing back to object storage.
Multi-Bucket Architecture
Object storage, as the most critical storage service provided by various cloud providers, offers 12 nines of data durability and up to 4 nines of availability. However, software failures can never be entirely eliminated, and object storage may still encounter significant software failures, rendering AutoMQ services unavailable.
On the other hand, in the cloud, multi-cloud, multi-region, and even hybrid cloud architectures are gradually emerging to meet enterprises' more flexible IT governance needs.
In light of this, the AutoMQ Business Edition innovatively employs a multi-bucket architecture to further enhance system availability and meet the more flexible IT governance needs of enterprises.
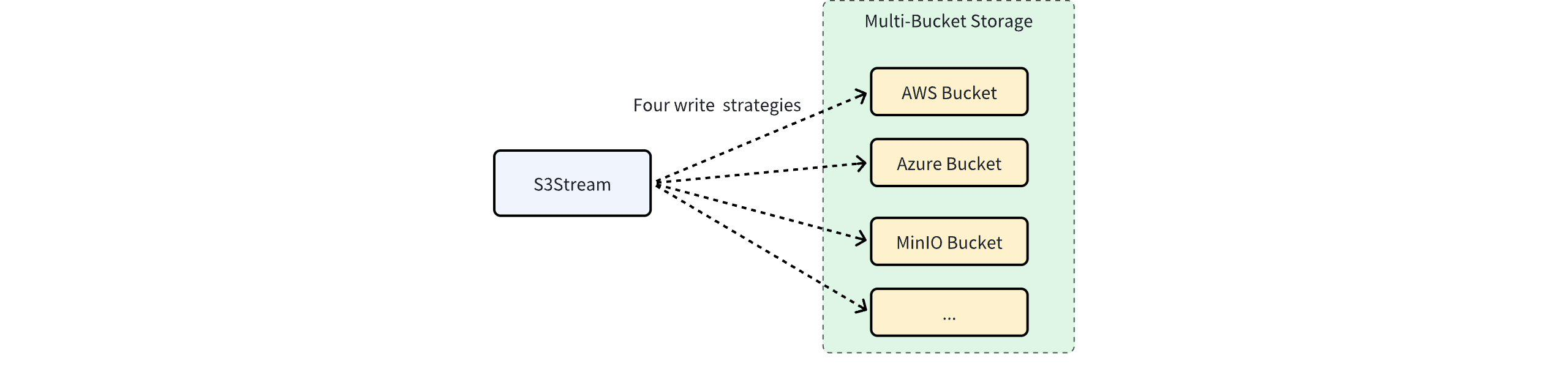
The AutoMQ Business Edition supports configuring one or multiple buckets for data storage, and S3Stream supports four writing strategies to cater to different business scenarios.
Round Robin
Multiple buckets are treated equally and written to in a round-robin fashion. This method is typically used to bypass bandwidth limitations imposed by cloud providers on a single bucket or account. For example, if one bucket only supports 5GiB/s bandwidth, combining two buckets can achieve a total of 10GiB/s, thus supporting large-scale traffic scenarios.
Failover
Object storage can still experience failures, and software-level failures might be more severe than zone-level failures. For business scenarios with extremely high availability requirements, data can be written to two buckets using a failover strategy. The bucket configuration in a failover scenario might be:
One primary bucket located in the same region as the business operations, where data is preferentially written.
A secondary bucket created in another region or even on another cloud. This bucket is connected to the primary region via a dedicated line or public internet. When the primary region's object storage is unavailable, new data is committed to the secondary bucket. Although the backup link incurs higher network costs, these costs are relatively controllable as they occur only when the primary bucket is unavailable.
This writing strategy greatly enhances AutoMQ's disaster recovery scenarios, allowing AutoMQ to build multi-region, multi-cloud, or even hybrid cloud disaster recovery architectures at a low cost.
Replication
In a failover multi-Bucket architecture, only write traffic can be redirected during a failure, and reads require delayed access. If your business cannot tolerate read delays during failures and requires a multi-active read-write architecture, you can configure the write strategy as replication. In this case, data will be synchronously written to multiple Buckets.
This approach is very costly and is only suitable for highly critical business operations.
Dynamic Sharding
Data is written to multiple Buckets in a dynamic and adjustable ratio, with round-robin being a specific scenario of this strategy. Dynamic sharding write methods are often suitable for multi-cloud and hybrid cloud architectures. In such architectures, different cloud service Buckets can be configured, or a combination of Public Cloud and Private Cloud object storage can be used. By dynamically adjusting the traffic ratio, the architecture can always possess the flexibility for multi-cloud migration and even cloud exit.