import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaTest {
private static final String BOOTSTRAP_SERVERS = "http://{}:9092"; // your automq broker ip
private static final int NUM_TOPICS = 50;
private static final int NUM_MESSAGES = 500;
public static void main(String[] args) throws Exception {
KafkaTest test = new KafkaTest();
// test.createTopics(); // create 50 topics
for(int i = 0; i < 100; i++){
test.sendMessages(); // 25,000 messages will be sent each time, and 500 messages will be sent to each of 50 topics.
}
}
public void createTopics() {
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
try (AdminClient adminClient = AdminClient.create(props)) {
List<NewTopic> topics = new ArrayList<>();
for (int i = 1; i <= NUM_TOPICS; i++) {
topics.add(new NewTopic("Topic-" + i, 1, (short) 1));
}
adminClient.createTopics(topics).all().get();
System.out.println("Topics created successfully");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
public void sendMessages() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
for (int i = 1; i <= NUM_TOPICS; i++) {
String topic = "Topic-" + i;
for (int j = 1; j <= NUM_MESSAGES; j++) {
String key = "key-" + j;
String value = "{\"userId\": " + j + ", \"action\": \"visit\", \"timestamp\": " + System.currentTimeMillis() + "}";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record, (RecordMetadata metadata, Exception exception) -> {
if (exception == null) {
System.out.printf("Sent message to topic %s partition %d with offset %d%n", metadata.topic(), metadata.partition(), metadata.offset());
} else {
exception.printStackTrace();
}
});
}
}
System.out.println("Messages sent successfully");
}
}
}
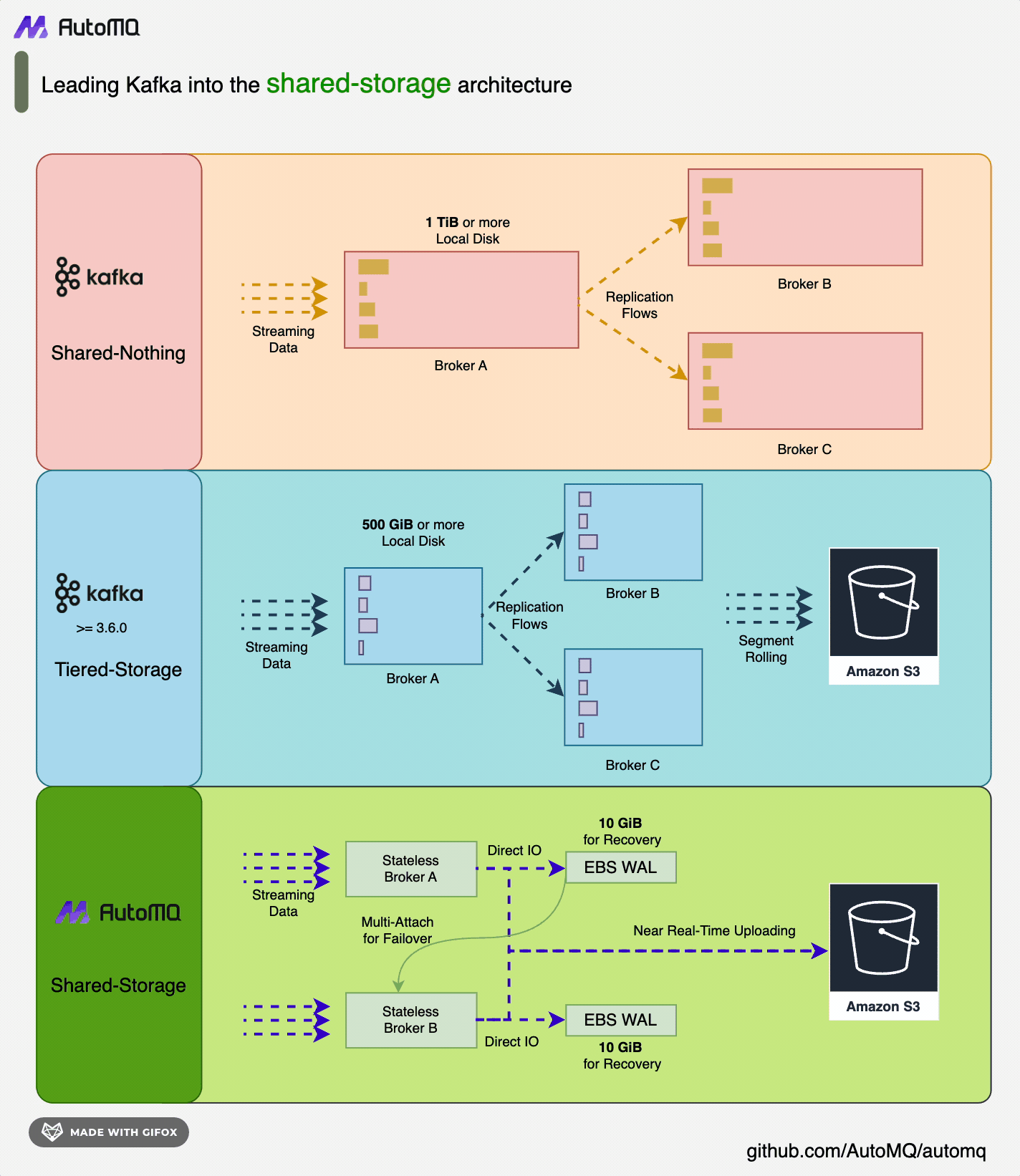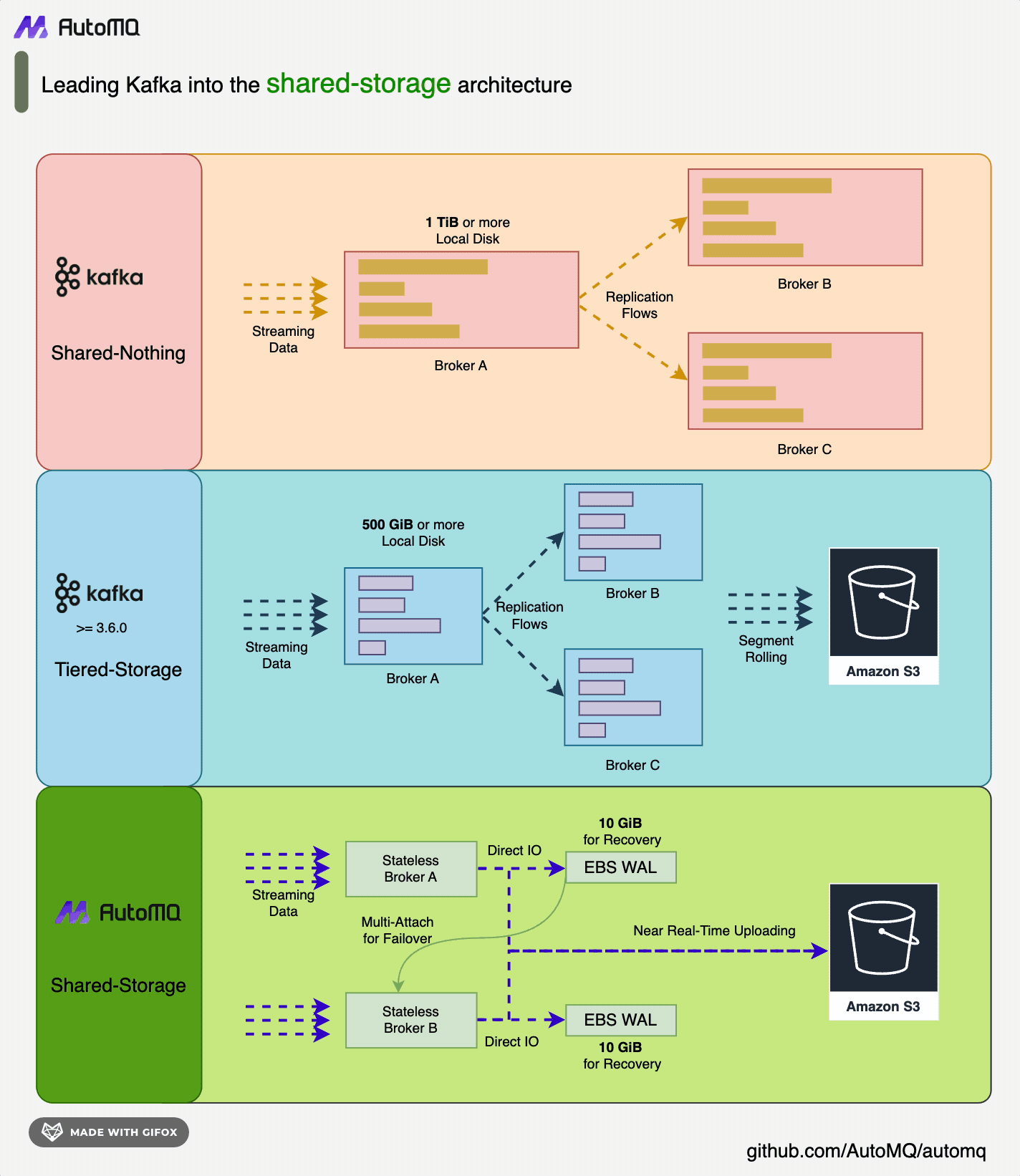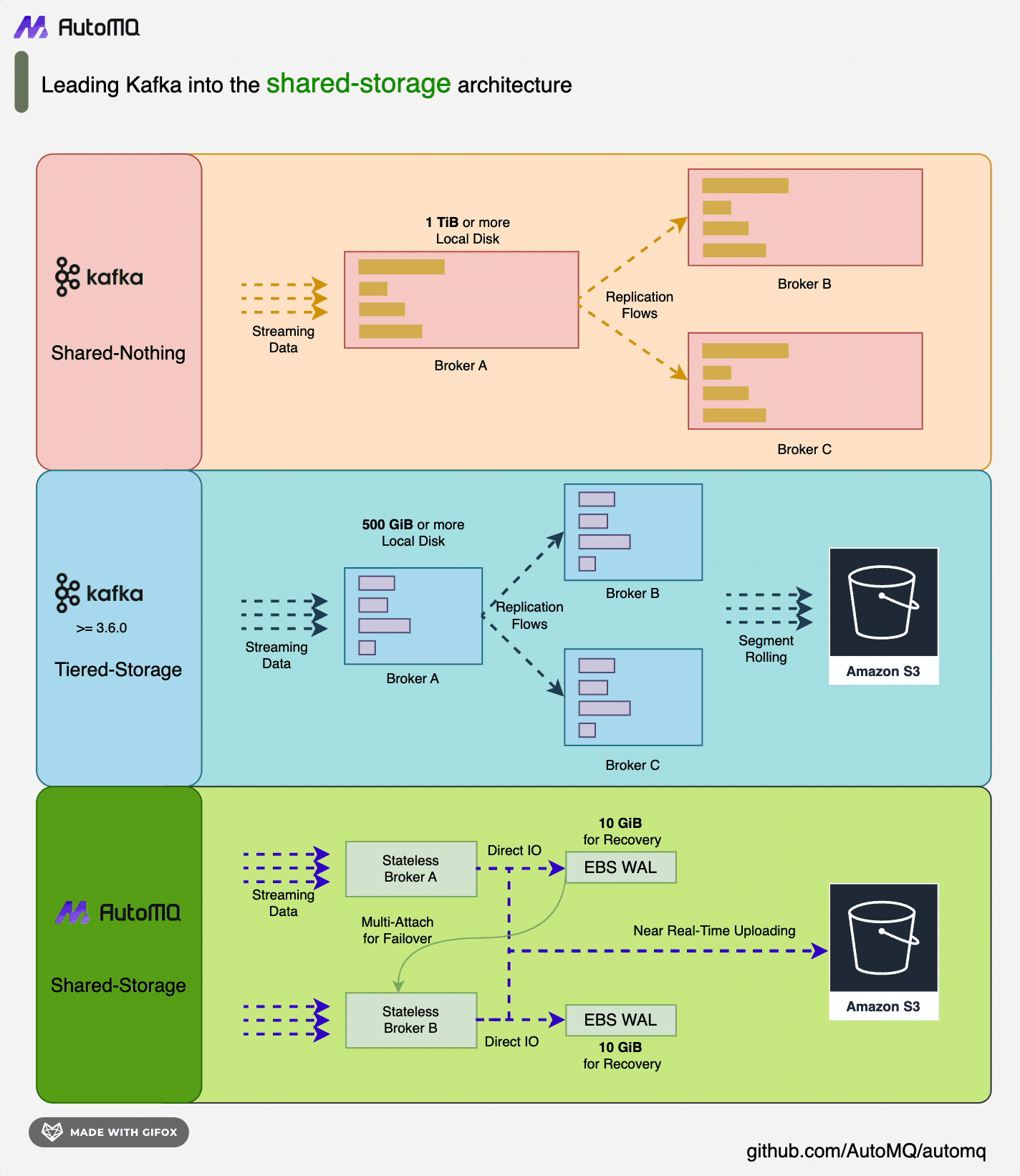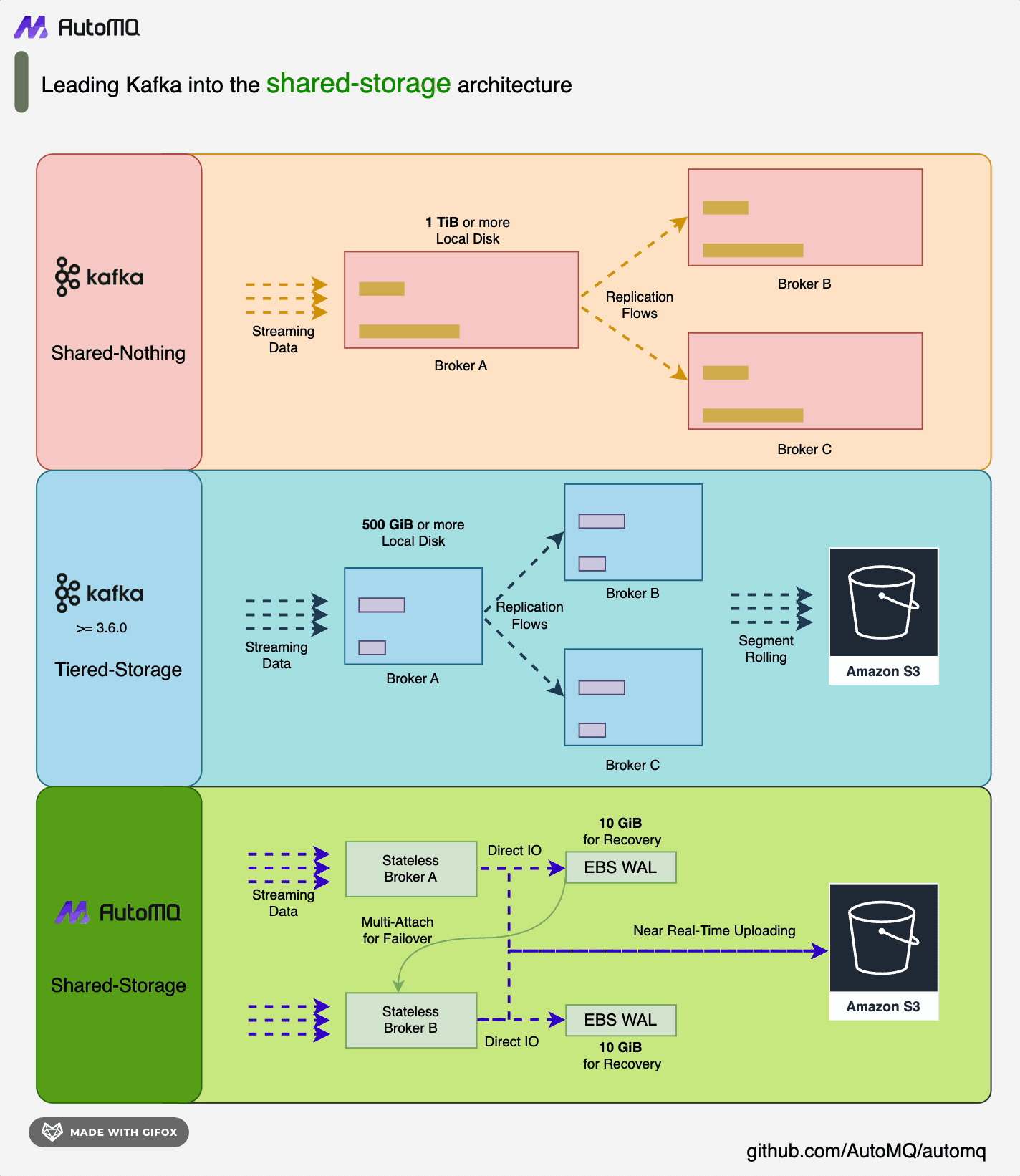
![夜莺架构 [3]](https://mintcdn.com/automq/sFBpuM1amdoj0ixs/zh/automq/integrations/observability/flashcat/2.webp?fit=max&auto=format&n=sFBpuM1amdoj0ixs&q=85&s=2edc6aa92eda5d663cb424a785b922f0)















