Comparison Conclusion
- 300x Efficiency Improvement in Partition Reassignment Compared to Apache Kafka: The partition reassignment speed of AutoMQ is approximately 300 times faster than that of Apache Kafka. AutoMQ transforms Kafka’s high-risk routine maintenance actions into automated, nearly imperceptible low-risk operational tasks.
- 4min to 1GiB/s Ultimate Elasticity: AutoMQ’s cluster can boost its emergency elasticity from 0 MiB/s to 1 GiB/s in just 4 minutes. This rapid scalability allows the system to accommodate sudden traffic spikes efficiently.
- 200x Cold Read Efficiency over Apache Kafka: AutoMQ optimizes performance by separating reads and writes, achieving a 200-fold reduction in send latency compared to Apache Kafka and a fivefold increase in throughput. AutoMQ handles peak shaving and filling for online messaging and offline batch processing scenarios.
Test Preparation
Configuration Parameters
AutoMQ is set to flush data to disk by default before responding, using the following settings:AutoMQ BYOC ensures high data reliability through the EBS multi-replica mechanism, so you don’t need to configure multiple replicas on the Kafka side.
Machine Specifications
When considering cost-effectiveness, small instance types combined with EBS are more advantageous than larger machines equipped with SSDs. For example, small instance r6in.large + EBS versus large instance i3en.2xlarge + SSD:- i3en.2xlarge, 8 cores, 64 GB memory, network baseline bandwidth 8.4 Gbps, with two 2.5 TB NVMe SSDs, maximum disk throughput of 600 MB/s; price $0.9040/h.
- r6in.large * 5 + 5 TB EBS, 10 cores, 80 GB memory, network baseline bandwidth 15.625 Gbps, EBS baseline bandwidth 625 MB/s; price (compute) 0.1743 * 5 + (storage) 0.08 * 5 * 1024 / 24 / 60 = $1.156/h.
- r6in.large: 2 cores, 16 GB memory, network baseline bandwidth 3.125 Gbps, EBS baseline bandwidth 156.25 MB/s; price $0.1743/h.
- GP3 EBS: The free tier includes 3000 IOPS and 125 MB/s bandwidth. Pricing for storage is 0.040 per MB/s per month and extra IOPS priced at $0.005 per month.
- AutoMQ uses EBS as a write buffer, requiring only 3 GB of storage, and leverages the free tier for IOPS and bandwidth.
- Apache Kafka stores all its data on EBS, with the required space determined by traffic and retention times in specific test scenarios. Additional EBS bandwidth of 31 MB/s is purchased, which further increases Apache Kafka’s unit cost per throughput.
Second-level Partition Reassignment
In a production environment, a Kafka cluster often serves multiple businesses. Fluctuations in business traffic and partition distribution may lead to insufficient cluster capacity or machine hotspots. Kafka operators need to scale the cluster and reassign hotspot partitions to idle nodes to ensure the cluster remains available. The time taken for partition reassignment determines the efficiency of emergency responses and operations:- The shorter the partition reassignment time, the quicker the cluster can scale to meet capacity demands, thus reducing the duration of any service impairment.
- Faster partition reassignment shortens the observation period for operators, allowing for quicker feedback and informed subsequent operational decisions.
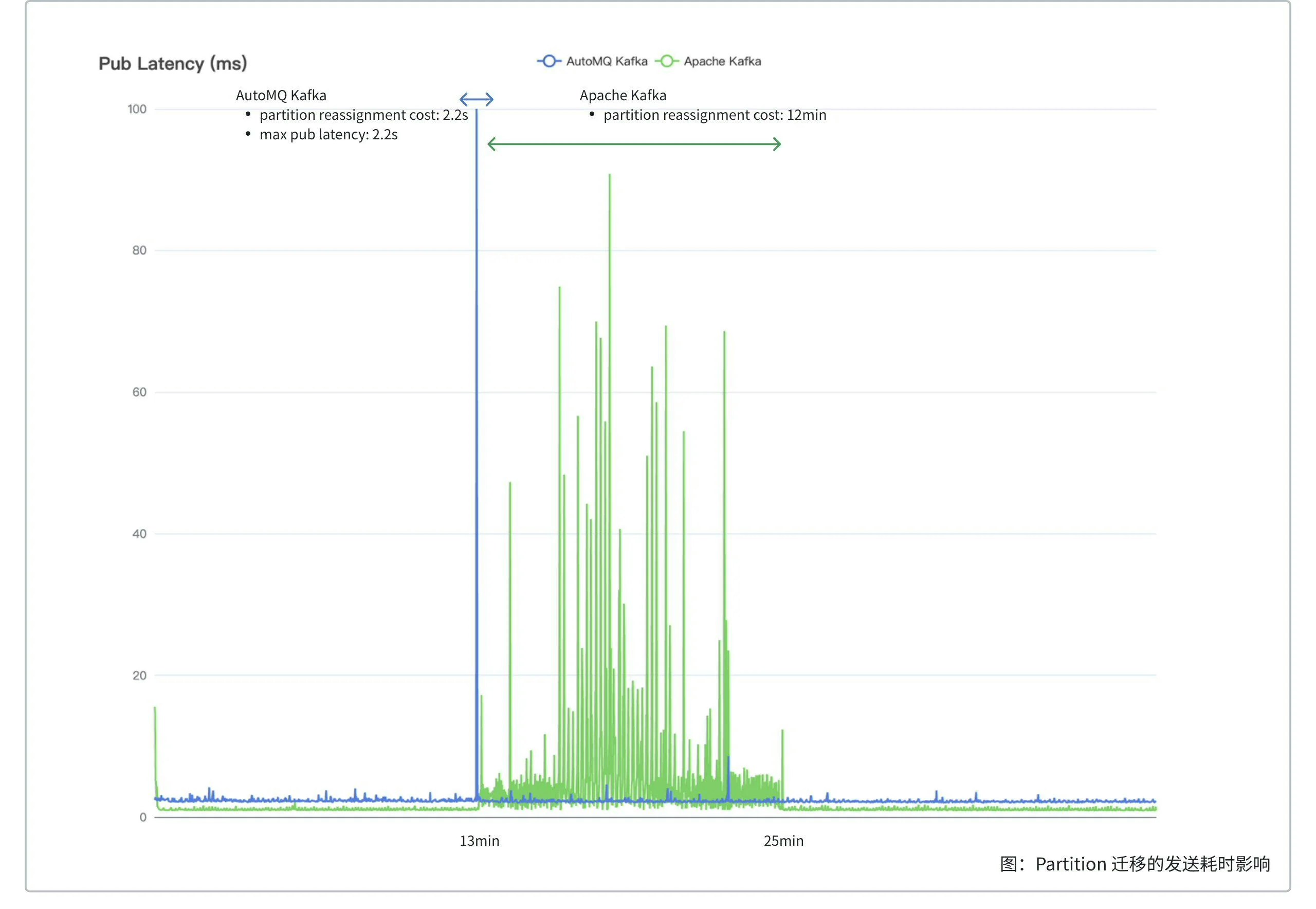
300x improvement in efficiency: AutoMQ reduces the time required for reassigning a 30 GiB partition compared to Apache Kafka from 12 minutes to just 2.2 seconds.
Test
This test assesses the reassignment time and the effects of moving a partition containing 30 GiB of data to a node without a replica of that partition, under typical send-consume traffic scenarios using AutoMQ and Apache Kafka. The specific test setup is as follows:-
Two r6in.large brokers are used to create:
- One single-partition, single-replica Topic A, with continuous read and write operations at a throughput of 40 MiB/s.
- A topic B with 4 partitions and a single replica was used, with a continuous read and write throughput of 10 MiB/s serving as background traffic.
Each Apache Kafka broker was additionally mounted with a 320GB 156MiB/s gp3 EBS for data storage.
| Comparison Item | AutoMQ | Apache Kafka |
|---|---|---|
| Reassignment Duration | 2.2s | 12min |
| Reassignment Impact | Maximum send latency of 2.2s | Continuous send latency within 12min fluctuating from 1ms to 90ms |
Analysis
The reassignment of AutoMQ partitions involves only uploading the buffered data from EBS to S3 to securely open on a new node, typically uploading 500 MiB within 2 seconds. The duration of AutoMQ partition reassignment is independent of the partition’s data volume, averaging around 1.5 seconds. During reassignment, AutoMQ partitions return a NOT_LEADER_OR_FOLLOWER error code to the client. Upon completion, the client updates to the new Topic routing table, internally retrying to send to the new node, temporarily increasing the partition’s send latency until it returns to normal levels after reassignment. Apache Kafka partition reassignment requires copying the partition’s replicas to a new node, catching up with new writes while copying historical data. The reassignment duration equals the partition’s data volume divided by (the reassignment throughput limit minus the partition’s write throughput). In real-world production environments, partition reassignment often takes hours; in this test, the reassignment of a 30 GiB partition took 12 minutes. Besides the lengthy reassignment, Apache Kafka needs to read cold data from the hard disk, and even with throttling, page cache contention can cause fluctuations in send latency, affecting service quality, depicted in the graph as the green curve’s jittery portions.0 -> 1 GiB/s Ultimate Elasticity
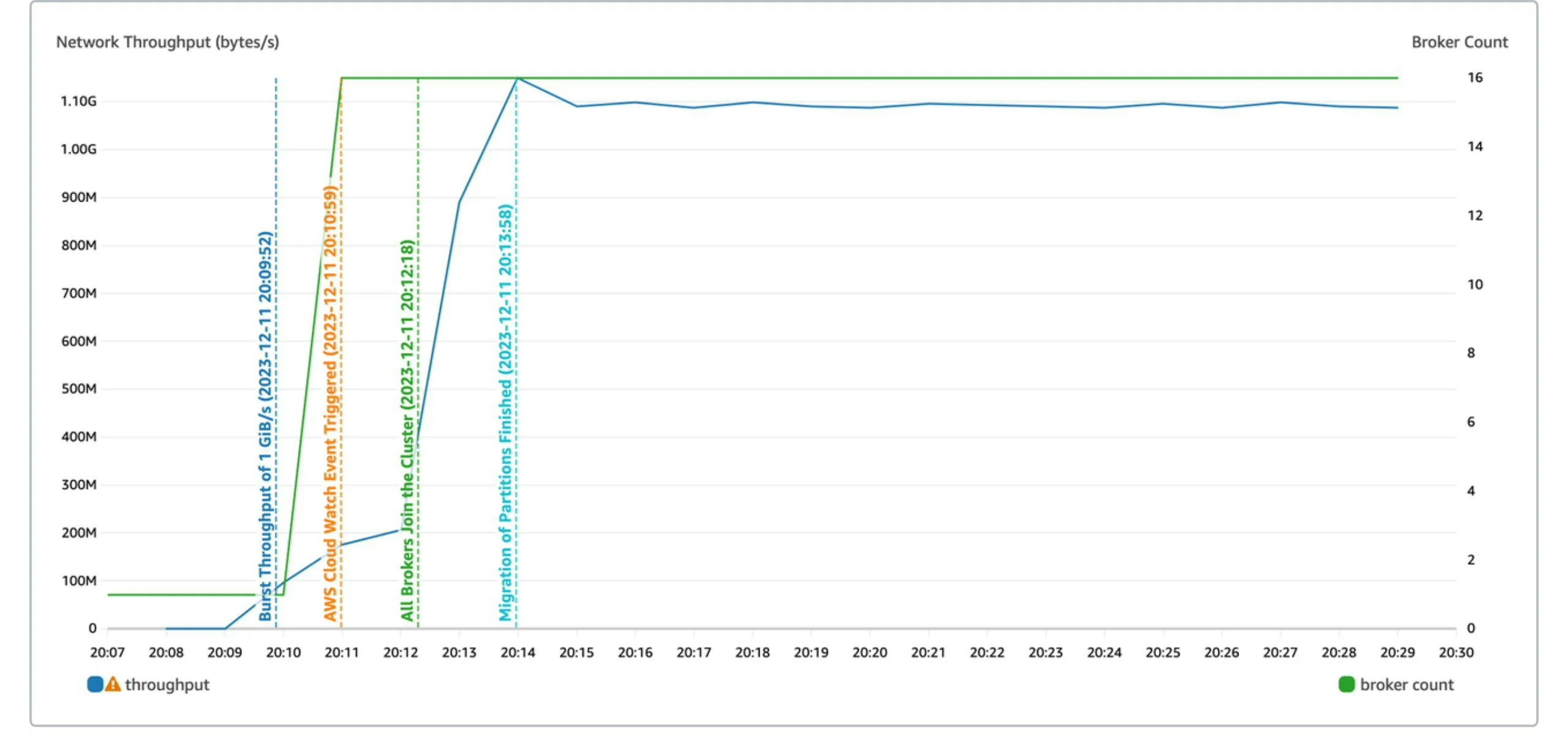
Kafka administrators typically plan Kafka cluster capacity based on historical experience, yet unexpected surges in traffic due to hot events and activities continually arise. In such cases, rapid cluster expansion and partition rebalancing become necessary to handle sudden spikes in traffic.With ultimate elasticity, the AutoMQ cluster can boost its emergency elasticity from 0 MiB/s to 1 GiB/s in just 4 minutes.
Test
The purpose of this test is to measure the emergency elasticity capability of AutoMQ, specifically the speed of expansion from 0 MiB/s to 1 GiB/s. The specific test scenario is as follows:- Initially, the cluster consists of only 1 Broker, with emergency elastic capacity set at 1 GiB/s, and a Topic with 1000 partitions is created.
- OpenMessaging is started to directly set the sending traffic to 1 GiB/s.
| Analysis Item | Monitoring Alert | Batch Expansion | Auto Balancing | Total |
|---|---|---|---|---|
| 0 -> 1 GiB/s Elastic Time | 70s | 80s | 90s | 4min |
Catch-up Read
Catch-up read is a common scenario in messaging and streaming systems:- In messaging, messages are typically used to decouple business processes and even out peaks and troughs. Smoothing peaks requires that the message queue holds the data sent upstream, allowing it to be consumed gradually downstream. In this scenario, the downstream systems read “catch-up” data that are cold and not in memory.
- In streams, periodic batch processing tasks may need to start scanning and computing data from several hours or even a day ago.
- There are additional fault scenarios: the consumer goes offline for several hours due to a failure and then comes back online; consumer logic issues are fixed, followed by a rewind to consume historical data.
- The speed of catch-up reads: The faster the catch-up reads, the more quickly the consumer can recover from the failure, and the faster batch processing tasks can produce analytical results.
- Isolation of reads and writes: Catch-up reads should aim to minimally impact the production rate and latency.
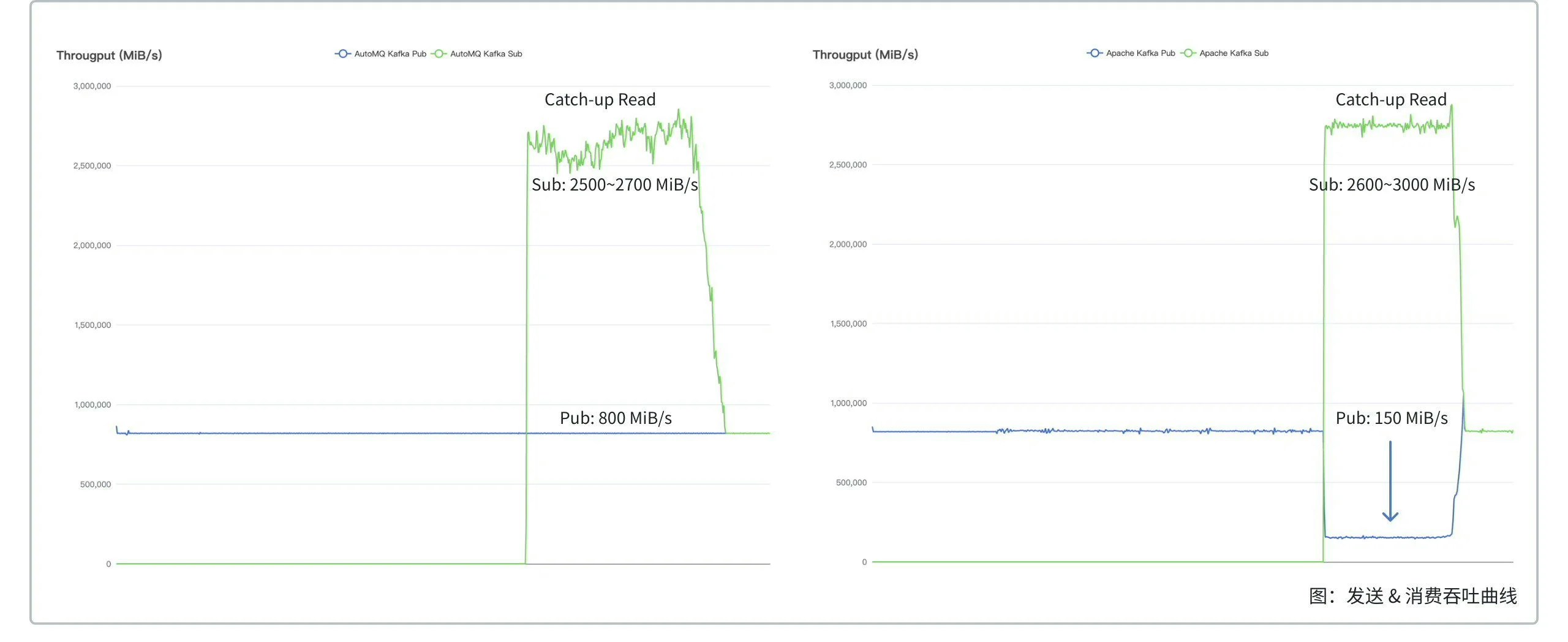
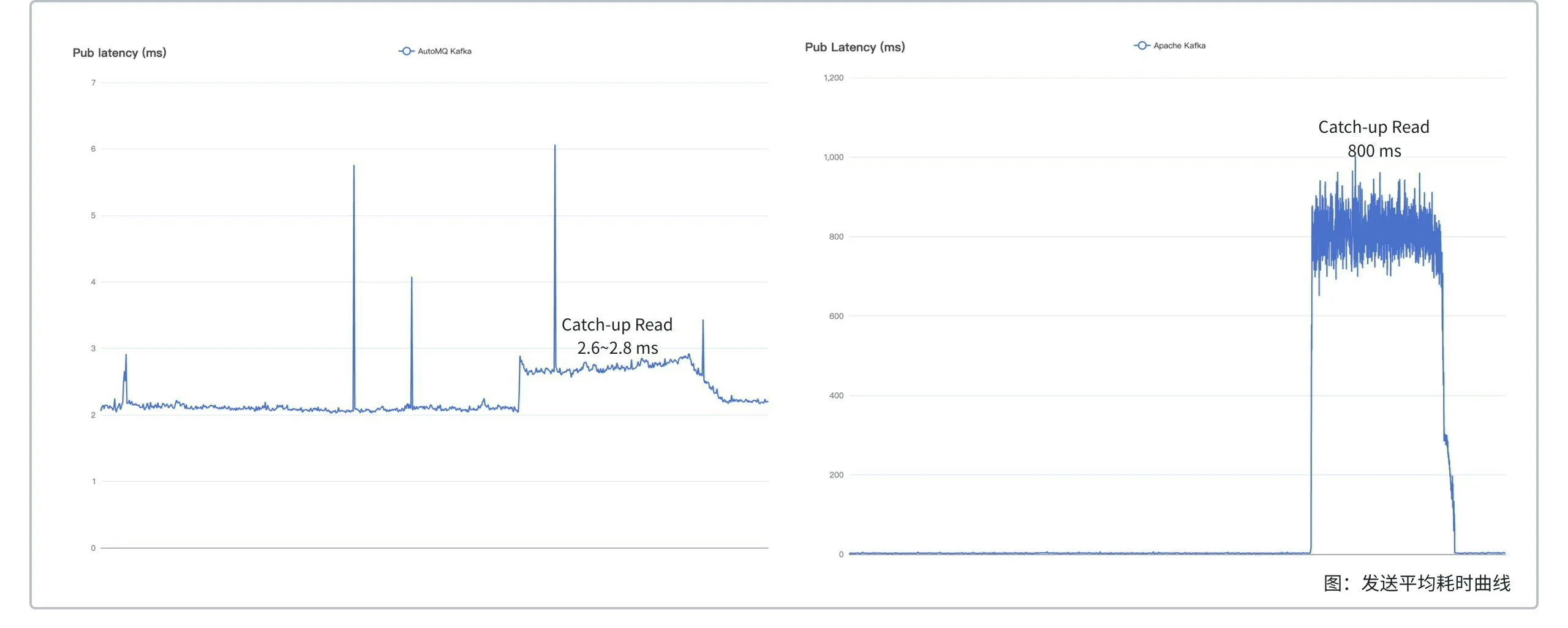
With a 200x efficiency improvement, AutoMQ’s read-write separation compared to Apache Kafka in catch-up read scenarios reduced sending time from 800ms to 3ms and shortened catch-up time from 215 minutes to 42 minutes.
Test
This test evaluates the catch-up read performance of AutoMQ and Apache Kafka using an identical cluster size. The test scenarios are outlined as follows:- Deploy a cluster with 20 Brokers and create a Topic with 1000 partitions.
- Continuously send data at a throughput of 800 MiB/s.
- After sending 4 TiB of data, initiate the consumer to consume from the earliest offset.
Each Apache Kafka broker is equipped with a separate 1000GB 156MiB/s gp3 EBS for data storage.
| Comparison Item | Send Latency During Catch-up Read | Impact on Send Throughput During Catch-up Read | Peak Throughput During Catch-up Read |
|---|---|---|---|
| AutoMQ | Less than 3ms | Read-write isolation, maintains 800 MiB/s | 2500 ~ 2700 MiB/s |
| Apache Kafka | Approximately 800ms | Interference, drops to 150 MiB/s | 2600 ~ 3000 MiB/s (at the expense of writes) |
Analysis
- In an equivalent cluster size scenario, during catch-up reads, AutoMQ’s sending throughput remains stable, whereas Apache Kafka’s sending throughput drops by 80%. This is because Apache Kafka performs disk reads during catch-up without IO isolation, consuming the read-write bandwidth of AWS EBS. This reduces the bandwidth available for writing to disk, thereby lowering sending throughput. In contrast, AutoMQ separates reads and writes by utilizing object storage for catch-up reads instead of the disk, which doesn’t consume disk read-write bandwidth and thus doesn’t affect sending throughput.
- For the same cluster size, during catch-up reads, the average send latency for AutoMQ rises by about 0.4 ms compared to just sending, while Apache Kafka’s latency surges to around 800 ms. This spike in send latency for Apache Kafka can be attributed to two factors: first, as noted earlier, catch-up reads consume AWS EBS read-write bandwidth, leading to decreased write throughput and increased latency; second, during catch-up reads, retrieving cold data from the disk contaminates the page cache, similarly resulting in higher write latency.
-
It’s important to note that when catching up to read 4 TiB of data, AutoMQ took 42 minutes, whereas Apache Kafka took just 29 minutes. The shorter time for Apache Kafka can be attributed to two reasons:
- During catch-up reads, Apache Kafka’s sending traffic was reduced by 80%, which decreased the amount of data it needed to handle while catching up.
- Apache Kafka does not implement I/O isolation, prioritizing reading speed over maintaining the sending rate.
- Assume that during catch-up reads, Apache Kafka maintains a sending rate of 700 MiB/s. Considering triple-replica writes that occupy EBS bandwidth, it would be 700 MiB/s * 3 = 2100 MiB/s.
- The total EBS bandwidth in the cluster is 156.25 MiB/s * 20 = 3125 MiB/s.
- The bandwidth available for reading is 3125 MiB/s - 2100 MiB/s = 1025 MiB/s.
- In a catch-up read scenario where data is simultaneously sent and read, reading 4 TiB of data would take 4 TiB * 1024 GiB/TiB * 1024 MiB/GiB / (1025 MiB/s - 700 MiB/s) / 60 s/min = 215 min.
Summary
This benchmark illustrates that AutoMQ, after redesigning Kafka for the cloud, offers substantial improvements in both efficiency and cost savings compared to Apache Kafka:- In partition reassignment scenarios, AutoMQ reduces the partition reassignment time of a 30GB partition from Apache Kafka’s 12 minutes down to 2.2 seconds, achieving a 300x efficiency improvement.
- With extreme elasticity, AutoMQ can scale out from 0 to 1 GiB/s in just 4 minutes to reach the desired capacity.
- In scenarios involving historical data catch-up reads, AutoMQ’s read-write separation not only improves average send latency by 200-fold, reducing it from 800ms to 3ms, but also achieves catch-up read throughput that is five times that of Apache Kafka.
Additional Notes
- AutoMQ supports AWS Graviton instances, and this performance comparison is equally applicable to instances supported by Graviton.
- When comparing cloud resource costs in an AWS environment, Apache Kafka incurs cross-availability zone traffic fees. AutoMQ can eliminate these fees through its cross-availability zone routing component. For details, refer to Save cross-AZ traffic costs with AutoMQ▸