| Comparison Item | AutoMQ | Apache Kafka |
|---|---|---|
| Compute | $2,859 | $18,447 |
| Storage | $5,961 | $69,984 |
| S3 API | $3,952 | $0 |
| Cross-availability zone traffic cost | $128 | $138,240 |
| Total | $12,899 | $226,671 |
Benchmark Preparation
Conduct performance testing on a Topic with 256 partitions at a traffic speed of 1 GiB/s for both production and consumption.AutoMQ Cluster
AutoMQ can be deployed on Kubernetes using the Bitnami Kafka Helm Chart. You can refer to Install AutoMQ by Helm Chart to deploy a 3-availability zone AutoMQ cluster on AWS:- A total of 6 nodes, including 3 servers and 3 brokers, are evenly distributed across 3 availability zones;
- The selected physical node type is m7g.4xlarge, featuring a specification of 16 cores and 64GB of RAM, a network baseline of 960 MiB/s, and priced at $476.544 per month.
Load Tester
Stress machines are deployed across 3 availability zones, with one m7g.4xlarge in each zone, simulating multi-availability zone business loads. The performance testing is conducted using theautomq-perf-test.sh script provided by AutoMQ, configured as follows:
-
A total of 60 Producers and 60 Consumers are evenly distributed across 3 availability zones, marked with
client.id=automq_az=apse1-az1to indicate the availability zone affiliation of the client. - Send 1,048,575 Records per second, each of 1 KiB in size, totaling 1 GiB/s of data.
-
Sending parameters are additionally configured with
batch.size=1048576andlinger.ms=100to achieve better batching performance, suitable for most high-throughput Kafka scenarios.
Costs
In a scenario where data is retained for 3 days (log.retention.hours=72), using AWS us-east-1 region as an example, the total cost of ownership for AutoMQ is $12,899 per month. The total cost includes expenses for computation, storage, S3 API, and cross-availability zone traffic.
- Computation: AutoMQ utilized 6 m7g.xlarge instances in this benchmarking scenario, totaling a computing resource cost of 6 * $476.544 = $2,859 per month.
- Storage: Traffic * 3 days * S3 price per unit = 1 * (60 * 60 * 24 * 3) * 0.023 = $5,961 per month.
- S3 API: Under this traffic, the average Get is 1,278/s and Put is 202.662/s, resulting in a cost of $3,952 per month.
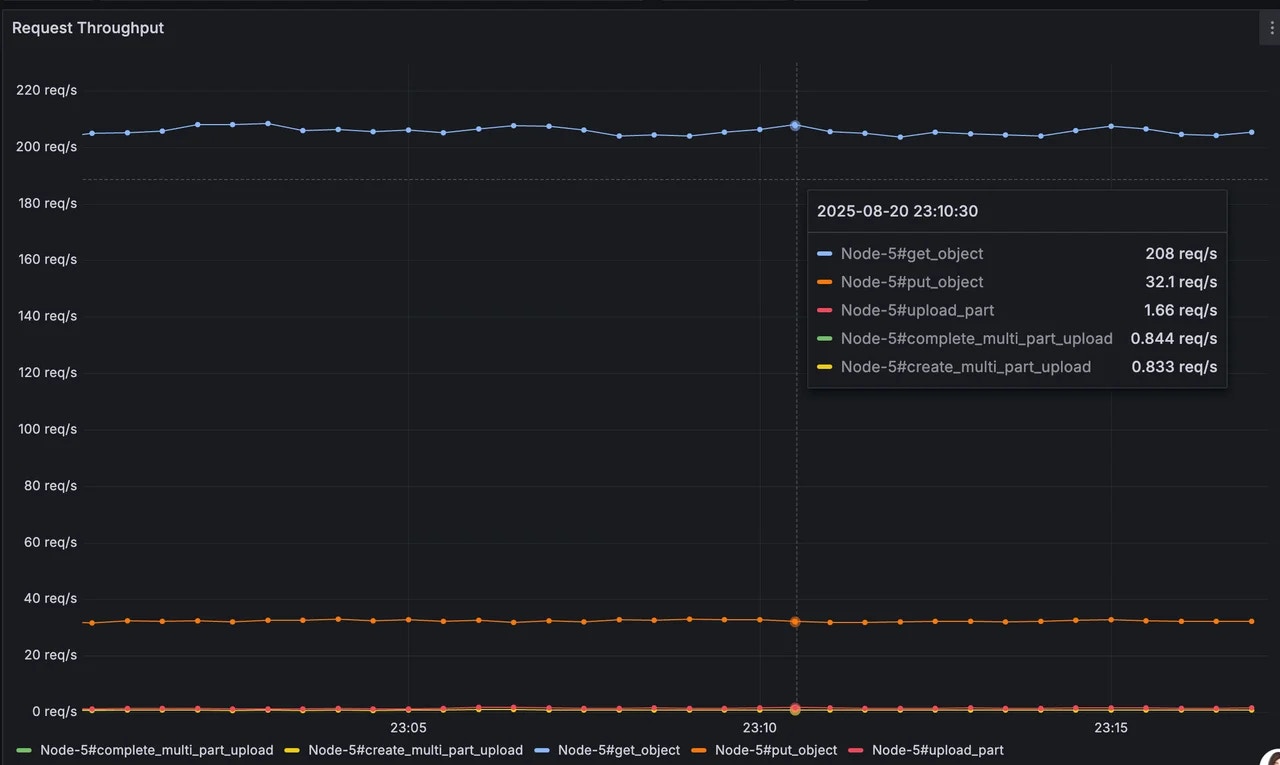
- Cross-availability zone traffic: Although AutoMQ is designed for clients to send and receive messages only with Brokers within the same availability zone, there is still a small amount of RPC requests between Brokers to synchronize KRaft metadata and forward ZoneRouterProduceRequest. We collected cross-availability zone traffic on Broker nodes using
iftop -t -s 60 -L 100. The average cross-availability zone Network In + Network Out for one node is 0.84 MiB/s. Therefore, the cross-availability zone traffic cost for 6 nodes is 0.84 / 1024 * 6 * (60 * 60 * 24 * 30) * 0.01 ~= $127 per month.
Compared to Apache Kafka, This Represents a 14x Cost Reduction.
The same workload on Apache Kafka requires $65,385 per month, which is 14 times that of AutoMQ. The total cost of ownership includes compute, storage, and Inter-Zone traffic.- Storage: To store 253.125 TiB of data (calculated as 1 / 1024 * (60 * 60 * 24 * 3)), and considering three replicas, 759.375 TiB of space is needed. Taking into account buffer and uneven data distribution, and assuming a 50% effective disk utilization rate, 1,518.75 TiB of disk space is necessary. To save on disk storage costs, st1 storage medium is used, leading to a storage cost calculation of 1,518.75 * 1024 * 0.045 = $69,984 per month.
- Compute: With a maximum EBS volume size of 16 TiB, at least 95 volumes are needed, corresponding to 95 Brokers. Following production practices, the minimum recommended instance type is r4.xlarge, costing $18,447.1 per month.
- Cross Availability Zone traffic: Assuming a uniform distribution of partitions and traffic, 2/3 of production traffic is sent across AZs. Consumption can be optimized to avoid cross AZ traffic using Fetch From Follower. Fetch From Follower implies that replicas are distributed across 3 AZs, generating two additional sets of production traffic among Broker ISR. Overall, cross AZ traffic is calculated as: production traffic * (2 / 3 + 2) * 30d = 1024 * (2 / 3 + 2) / 1024 * (60 * 60 * 24 * 30) * 0.02 = $138,240 per month.
- AutoBalancing: AutoMQ includes a load balancing component within the Controller, which automatically balances the load based on traffic between nodes. Partition reassignment is completed in less than 2 seconds, eliminating the need for manual load balancing by operations personnel.
- No Overprovisioning: With stateless nodes and second-level partition reassignments, AutoMQ can scale up or down within minutes—most of the time is spent on resource preparation. After expansion, load balancing is completed in seconds. AutoMQ does not require pre-reserving resources for peak times or handling load balancing at the hour level.
Performance:
The CPU utilization of each AutoMQ Broker is at 50%. There is ample idle CPU capacity to handle traffic spikes and more small packet requests.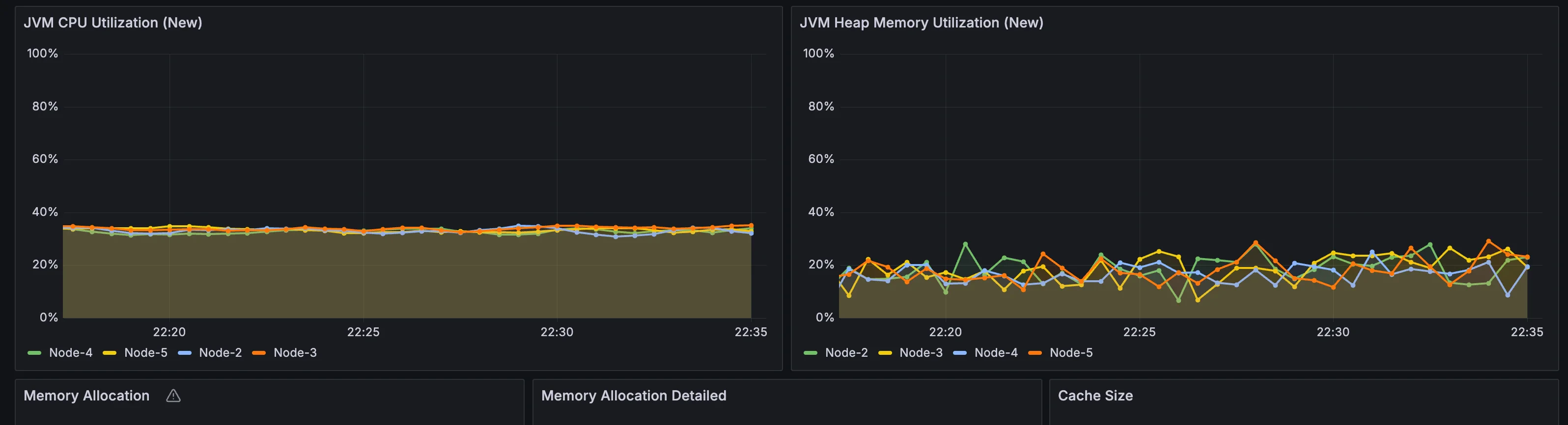
| - | AVG | P50 | P99 | P999 |
|---|---|---|---|---|
| Produce | 472ms | 465ms | 823ms | 1049ms |
| E2E | 631ms | 602ms | 1189ms | 1549ms |
batchInterval parameter in the configurations of s3.wal.path and automq.zonerouter.channels to reduce the wait time for batching writes to S3. However, achieving lower latency will increase the cost of S3 APIs.