与 Apache Kafka 的区别
架构:Shared Nothing vs Shared Storage
Apache Kafka 使用本地磁盘介质,通过软件层面的高可用副本复制逻辑(ISR 机制)构建一套高可靠存储,对业务逻辑侧提供一种“无限”的流式存储抽象。所有的 Kafka 数据都是按照特定的逻辑存储在本地磁盘介质上,上述思路一般称为 Shared Nothing 架构。 AutoMQ 区别于 Apache Kafka,采用了存算分离的思路,不再使用本地磁盘,而是使用共享的对象存储服务来保存数据。AutoMQ 抽象了一个 S3Stream 流存储库(软件库)来代替 Apache Kafka 的本地 Log 存储,在保证上层 Apache Kafka 功能语义不变的前提下,透明地使用了对象存储来保存 Kafka 数据,上述架构称为 Shared Storage 架构。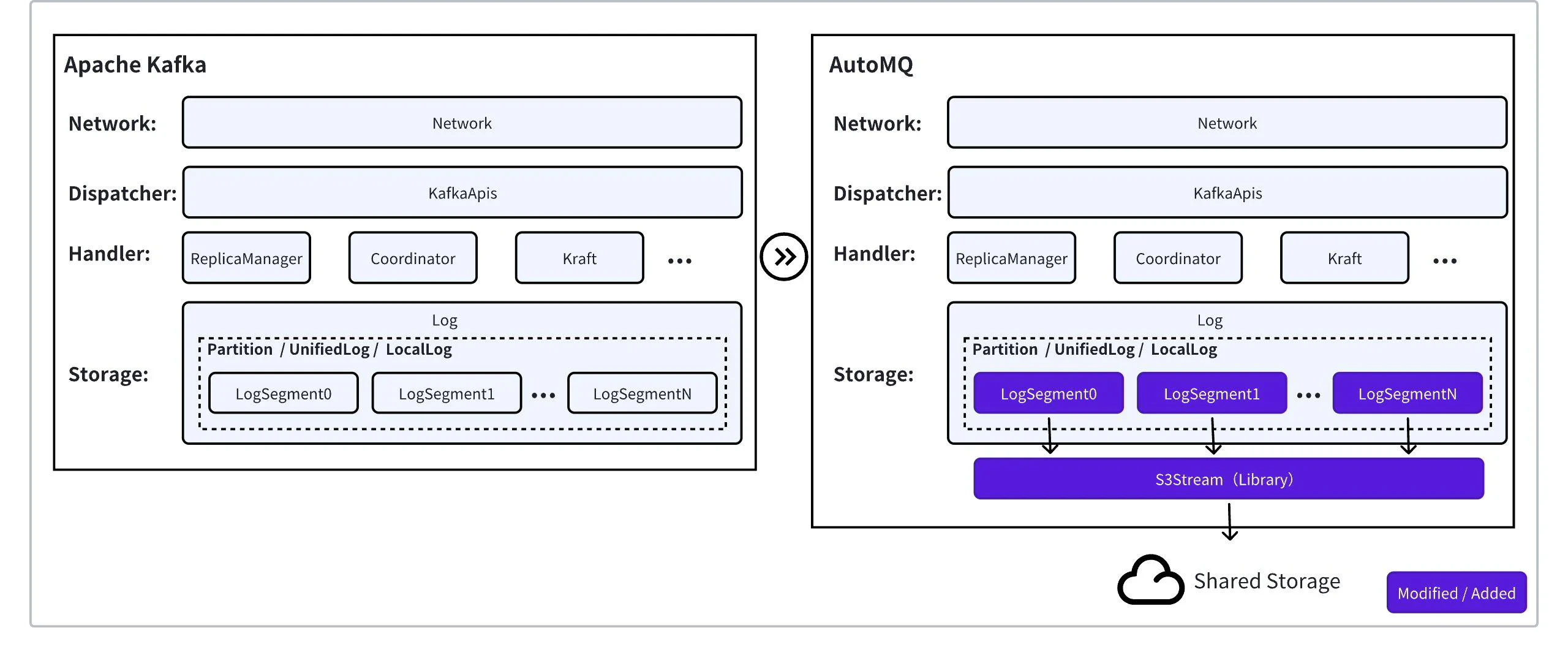
| Apache Kafka 采用 Shared Nothing 架构 | AutoMQ 采用 Shared Storage 架构 |
|---|---|
| 数据在本地磁盘,需要实现跨节点多副本复制 | 数据在 S3 共享存储(三副本高可靠),无需实现多副本复制 |
| 数据在各节点间隔离,数据访问绑定节点 | 数据在各节点间共享,可以跨节点共享访问 |
| 增加节点水平扩展、替换故障节点时需要重新迁移分片数据 | 增加节点、替换故障节点,无需迁移数据即可快速切换 |
说明:Apache Kafka 自 3.6 版本开始规划分层存储能力(暂未生产可用),支持将历史数据卸载到对象存储服务中,该架构和 AutoMQ 完全依赖对象存储构建存储层有一定的相似性和区别。详细对比可参考与多级存储的区别▸。
弹性:秒级分区迁移 vs 小时级分区迁移
分区迁移是 Kafka 生产环境中高频遇到且不可绕过的问题,在局部节点故障、集群扩缩容、局部热点处理 等场景中都需要进行分区迁移。 Apache Kafka 使用 Shared Nothing 架构,每个分区的数据全部存储在特定的存储节点。如果涉及到分区迁移,则需要将分区的全量数据搬迁到新的目标节点才能提供服务。上述过程存在耗时长、耗时不确定的问题。举例:以一个 100MiB/s 写入吞吐的 Kafka 分区为例,一天内产生的数据量约为 8.2TiB,如果需要迁移该分区则需要将全部数据搬迁到其他节点。即使分配 1Gbps 的网络带宽,也需要小时级耗时才能完成迁移。
成本:10 倍成本差异
参考上文技术架构的差异,AutoMQ 和 Apache Kafka 在计算、存储的成本结构上同样存在较大差异。AutoMQ 在消息写入时无需做跨节点多副本复制,可以节省大部分的跨节点复制流量和压力。同时,AutoMQ 使用 S3 对象存储作为存储介质,在典型的公共云环境下,对象存储的成本远低于挂载到各节点的 EBS 块存储。 具体对比项目如下:| 成本对比 | Apache Kafka | AutoMQ |
|---|---|---|
| 存储单价 |
|
|
| 跨节点复制流量 |
|
|
备注:上述存储单价是以 AWS S3 美国东部 EBS GP3 实例和 S3 标准型存储对比,详细信息参考链接。上述跨节点流量复制成本以 AWS AZ 间流量传输成本为例。关于 AutoMQ 和 Apache Kafka 的详细成本对比,参考AutoMQ vs. Apache Kafka 性能和成本对比▸。
容量: Reserved vs Pay-as-you-go
容量规划是 Kafka 大规模应用于生产场景的另一难题。由于 AutoMQ 和 Apache Kafka 的架构差异以及存储介质的差异,在容量规划层面有所差异:| Apache Kafka 使用本地磁盘、存算一体 | AutoMQ 使用 S3 对象存储、存算分离 |
|---|---|
| 磁盘空间需要提前预留 | 存储空间无需预留,按需使用、按量付费 |
| 单节点存储有限,存储扩展性差 | S3 对象存储空间近乎无限,存储扩展性好 |