Differences from Apache Kafka®
Architecture: Shared Nothing Vs Shared Storage
Apache Kafka® uses local disk storage and constructs a highly reliable storage system through software-level high availability replica replication logic (ISR mechanism). This provides a “limitless” stream storage abstraction to the business logic side. All Kafka® data is stored on local disk media according to specific logic, a method generally referred to as a Shared Nothing architecture. AutoMQ differs from Apache Kafka® by adopting a compute-storage separation approach. Instead of using local disks, it uses shared object storage services to store data. AutoMQ abstracts an S3Stream storage repository (software library) to replace Apache Kafka®‘s local log storage. This transparent use of object storage to store Kafka® data while ensuring the upper layer Apache Kafka® functionalities and semantics remain unchanged is known as a Shared Storage architecture.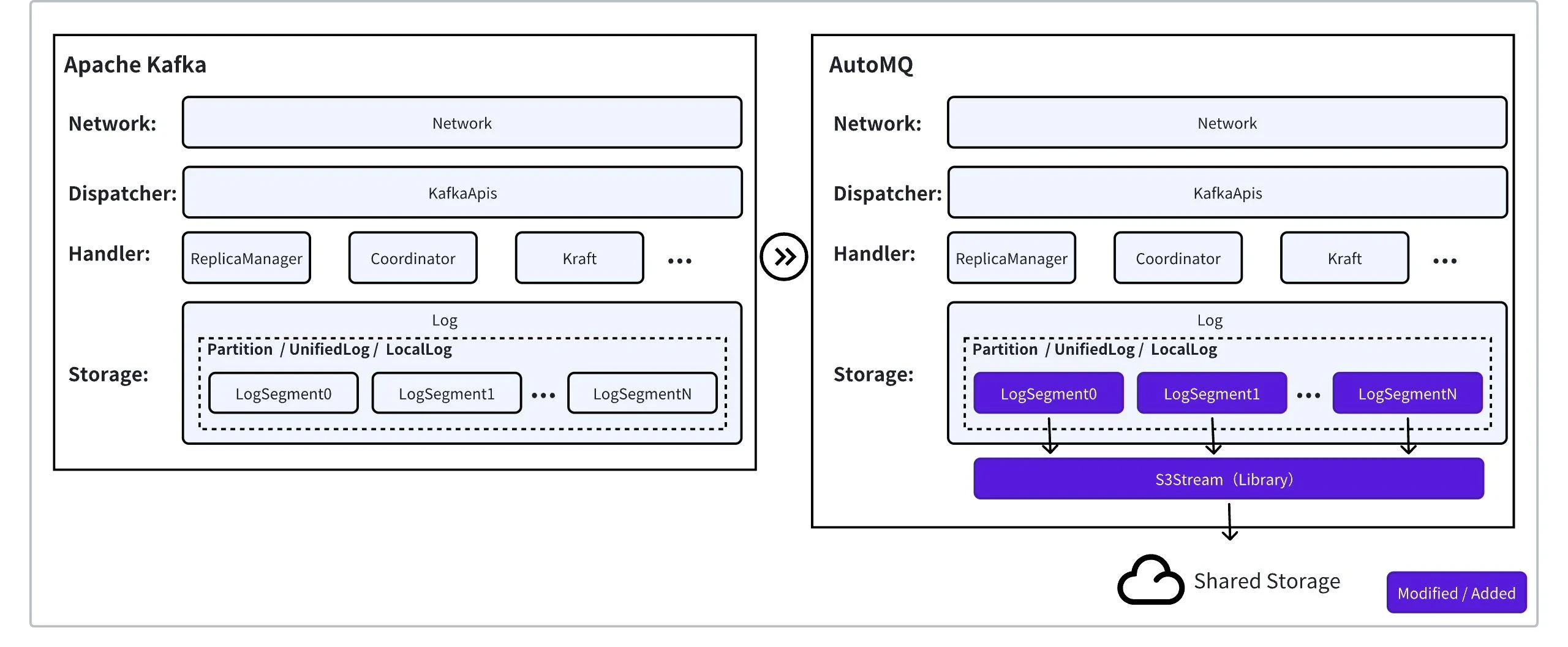
| Apache Kafka Utilizes Shared Nothing architecture | AutoMQ Utilizes Shared Storage architecture |
|---|---|
| Data is stored on local disks, requiring cross-node multiple replica replication | Data is stored in S3 shared storage (high reliability with three replicas), eliminating the need for multiple replica replication |
| Data is isolated across nodes, and data access is bound to specific nodes. | Data is shared across nodes, allowing cross-node access. |
| When adding nodes for horizontal scaling or replacing faulty nodes, shard data must be reassigned. | When adding nodes or replacing faulty nodes, data reassignment is not needed for quick switching. |
Since version 3.6, Apache Kafka has been planning tiered storage capabilities (not yet production-ready), which supports the offloading of historical data to object storage services. This architecture shares certain similarities and differences with AutoMQ, which fully relies on object storage to construct its storage layer. For a detailed comparison, see Difference with Tiered Storage▸.
Flexibility: Second-level Partition Reassignment vs. Hour-level Partition Reassignment
Partition reassignment is a frequent and unavoidable issue in Apache Kafka production environments, required in scenarios like partial node failures, cluster scaling, and partial hotspot handling. Apache Kafka uses a Shared Nothing architecture, where each partition’s data is stored entirely on specific storage nodes. When partition reassignment is involved, the full data of the partition must be transferred to the new target node before service can be provided. This process can be time-consuming and unpredictable.Example:For a Kafka partition with a write throughput of 100MiB/s, the data generated in one day is approximately 8.2TiB. If this partition needs to be reassigned, all the data must be moved to another node. Even with a network bandwidth of 1Gbps, it would take hours to complete the reassignment.
Cost: 10x Cost Difference
Referencing the above architectural differences, AutoMQ and Apache Kafka also have significant cost structure differences in terms of computing and storage. AutoMQ does not require cross-node multiple replica replication when writing messages, saving most of the cross-node replication traffic and pressure. Additionally, AutoMQ uses S3 object storage as the storage medium, which is far less costly than mounting EBS block storage to each node in typical Public Cloud environments. The specific comparison items are as follows:| Cost Comparison | Apache Kafka | AutoMQ |
|---|---|---|
| Storage Unit Price |
|
|
| Cross-Node Replication Traffic |
|
|
The storage unit prices above are based on a comparison between AWS S3 US East EBS GP3 instances and S3 Standard storage. For detailed information, refer to AWS S3 Pricing.The cross-node replication traffic costs above are based on the cost of data transfer between AWS AZs.For a detailed cost comparison between AutoMQ and Apache Kafka, refer to AutoMQ vs. Apache Kafka Benchmarks and Cost▸.
Capacity: Reserved Vs Pay-as-you-go
Capacity planning is another challenge when Kafka is applied on a large scale in production environments. Due to the architectural differences and storage media differences between AutoMQ and Apache Kafka, there are differences in capacity planning:| Apache Kafka Uses local disks, integrated storage and compute | AutoMQ Uses S3 object storage, separated storage and compute |
|---|---|
| Disk space must be reserved in advance | Storage space is on-demand, pay-as-you-go |
| Limited storage on a single node, poor storage scalability | S3 object storage space is nearly unlimited, with good storage scalability |