- Based on AWS public pricing, Amazon S3 Standard storage is priced at approximately 0.20/GiB/month) on a per-GiB single-replica basis. Additionally, object storage inherently offers multi-availability zone availability and durability, eliminating the need for additional data replication. Compared to the traditional 3-replica architecture based on EBS gp3 (approximately $0.60/GiB/month total), this can reduce storage costs by roughly 26×.
- The shared storage architecture, in contrast to the Shared-Nothing architecture, truly embodies storage-compute separation, where data is not bound to computing nodes. Consequently, AutoMQ can perform partition reassignment without data duplication, achieving truly lossless partition reassignment in seconds. This capability is fundamental to supporting AutoMQ’s real-time traffic self-balancing and second-level node horizontal scaling.
S3 Storage Architecture
- Stream Set Object: When uploading WAL data, the majority of smaller Streams are consolidated and uploaded as a single Stream Set Object.
- Stream Object: The Stream Object contains data from a single Stream, facilitating precise data deletion for Streams with different lifecycles.
- Metadata Stream: This stream stores data indices, Kafka LeaderEpoch snapshots, Producer snapshots, and other metadata.
- Data Stream: This stream holds the complete Kafka data within the partition.
StreamSet Object Compact
StreamSet Object Compaction is performed periodically in the background on the Broker at 20-minute intervals. Similar to RocksDB SST, StreamSet Object Compaction selects an appropriate list of StreamSet Objects on the current Broker based on certain policies and merges them using a merge sort method:- Streams that exceed 16MiB after merging will be split into individual Stream Objects and uploaded separately;
- The remaining Streams are merged and written into a new StreamSet Object using merge sort.
Stream Object Compact
The core purpose of Stream Object Compact is to minimize the total amount of metadata required to maintain object mapping in the cluster and to improve the aggregation of Stream Object data, thereby reducing API call costs for cold data catch-up read. Stream Objects involved in Compact are typically already 16MB, meeting the minimum part limit of object storage. Stream Object Compact uses the MultiPartCopy API of object storage to directly perform range copy uploads, avoiding the waste of network bandwidth from reading and then writing back to object storage.Multi-Bucket Architecture
As one of the most critical storage services offered by various cloud providers, object storage provides twelve nines of data durability and up to four nines of availability. However, software failures can never be completely eliminated, and object storage can still experience significant software failures, rendering AutoMQ services unavailable. On the other hand, multi-cloud, multi-region, and even hybrid cloud architectures are gradually emerging to meet enterprises’ more flexible IT governance needs. In view of this, AutoMQ commercial editions innovatively adopt a multi-bucket architecture to further enhance system availability and meet enterprises’ more flexible IT governance needs.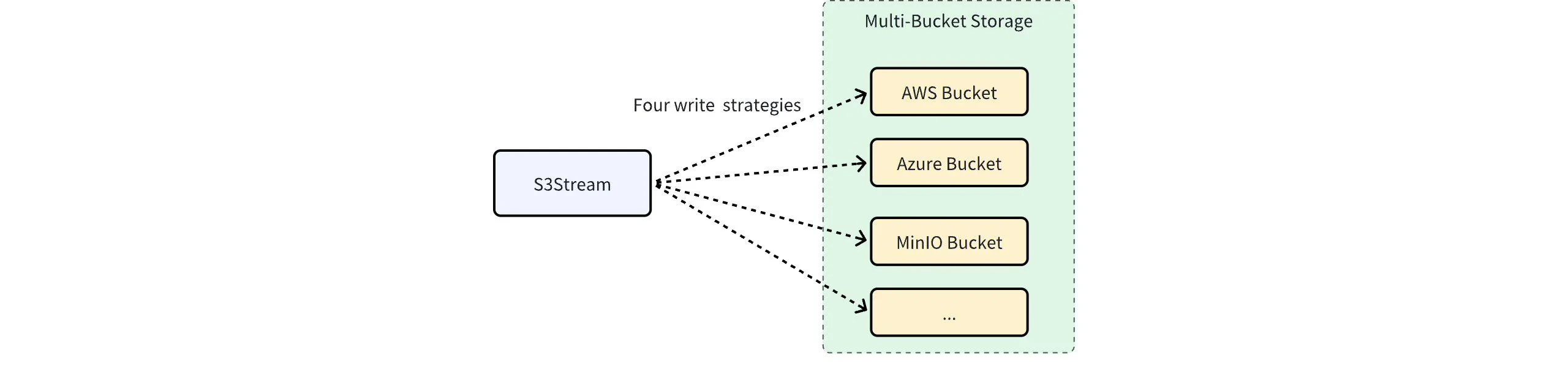
Round Robin
Multiple Buckets are treated equally, and data is written to them in a round-robin manner. This method is generally used to bypass the bandwidth limitations imposed by Cloud providers on a single Bucket or account. For instance, if a single Bucket supports only 5 GiB/s of bandwidth, combining two Buckets can achieve 10 GiB/s of bandwidth, supporting ultra-high traffic business scenarios.Failover
Object storage can still experience failures, and software-level failures can sometimes be more severe than zone-level failures. For business scenarios with extremely high availability requirements, data can be written to two Buckets using a failover approach. The Bucket configuration in a failover scenario might be:- One as the primary Bucket, located in the same region as the business, where data is preferentially written.
- Another as a standby Bucket, created in a different region or even on a different Cloud. Connectivity between the primary and standby regions is established through dedicated lines or the public internet. When the primary region’s object storage is unavailable, new data is submitted to the standby Bucket. Although the standby link incurs higher network costs, these costs are relatively controllable since they only occur when the primary Bucket is unavailable.