How AutoMQ Achieves Smooth Scaling in Seconds
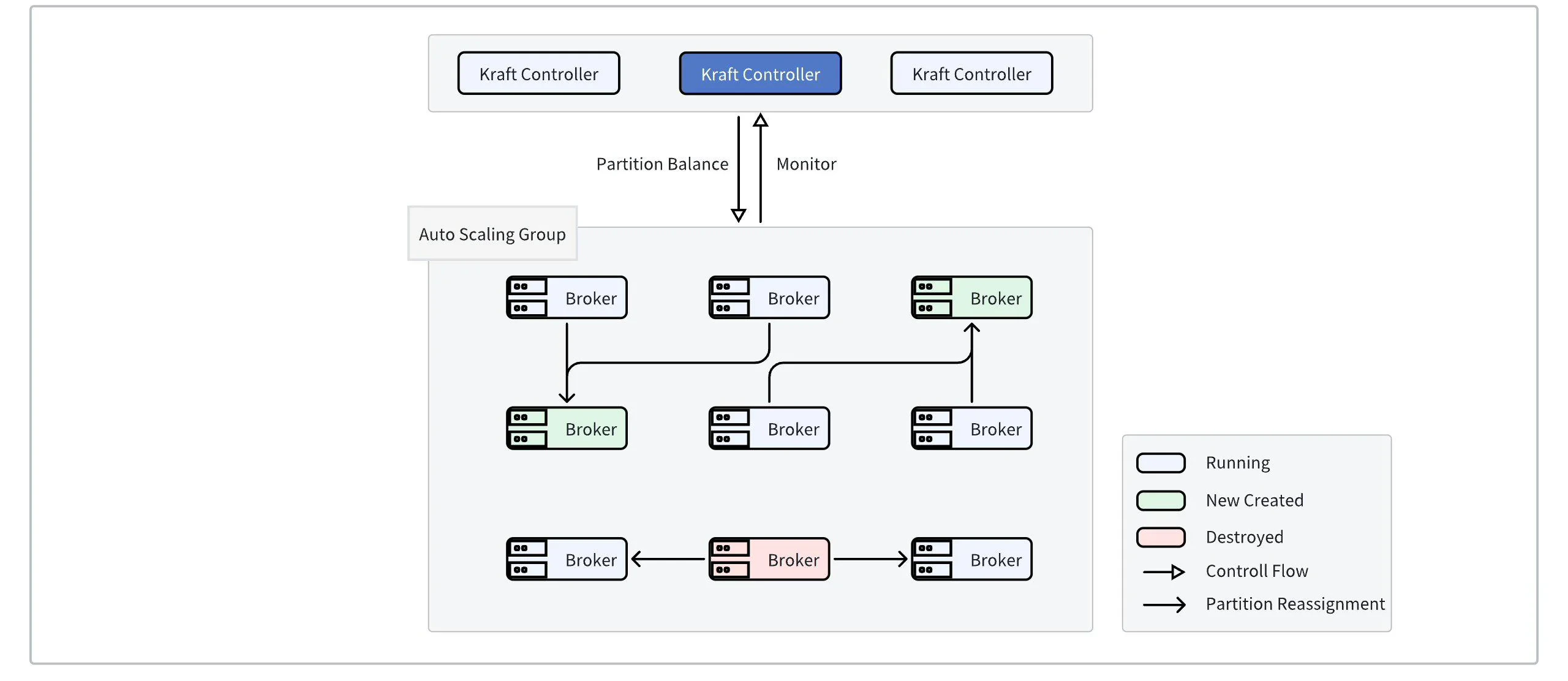
Triggering Scaling
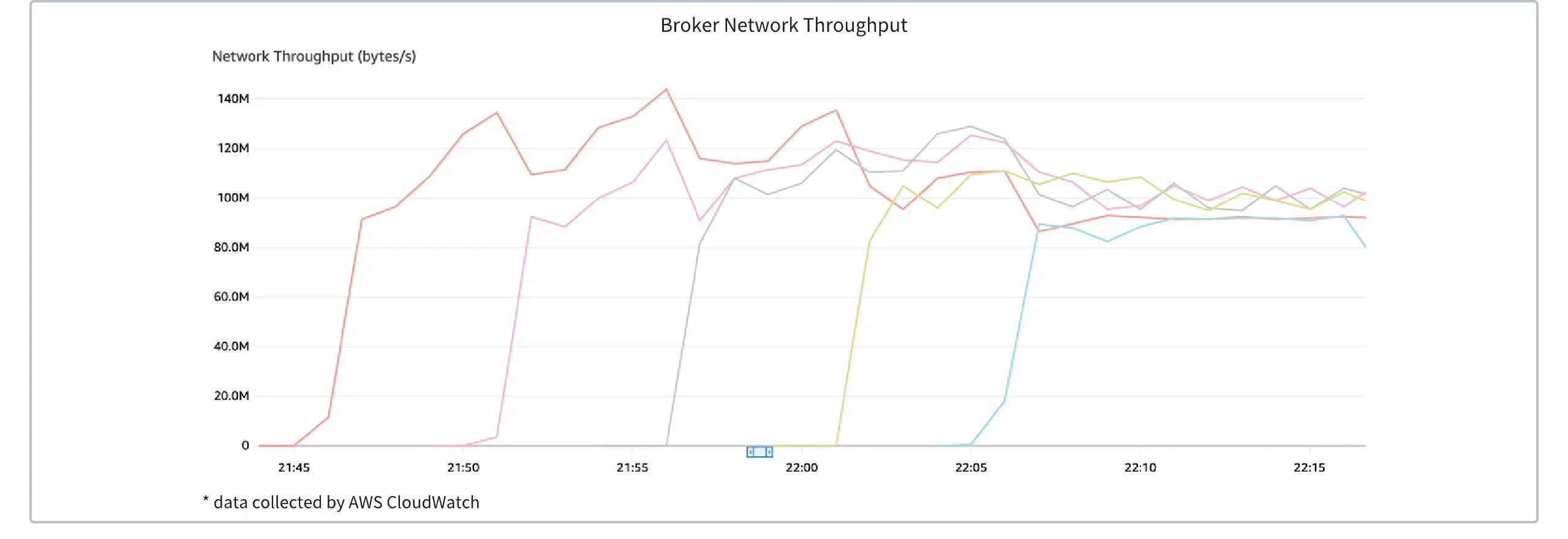
Taking AWS Auto Scaling Groups (ASG) as an example, by configuring traffic threshold monitoring, when the cluster traffic reaches the scaling threshold, new broker nodes are automatically launched. At this point, the Controller detects the traffic imbalance and automatically moves partitions to the newly created brokers, completing the traffic redistribution. The figure below shows the change in the number of brokers in an AutoMQ Kafka cluster as the traffic increases. It can be seen that brokers are dynamically created and added to the cluster to balance the load as traffic increases linearly.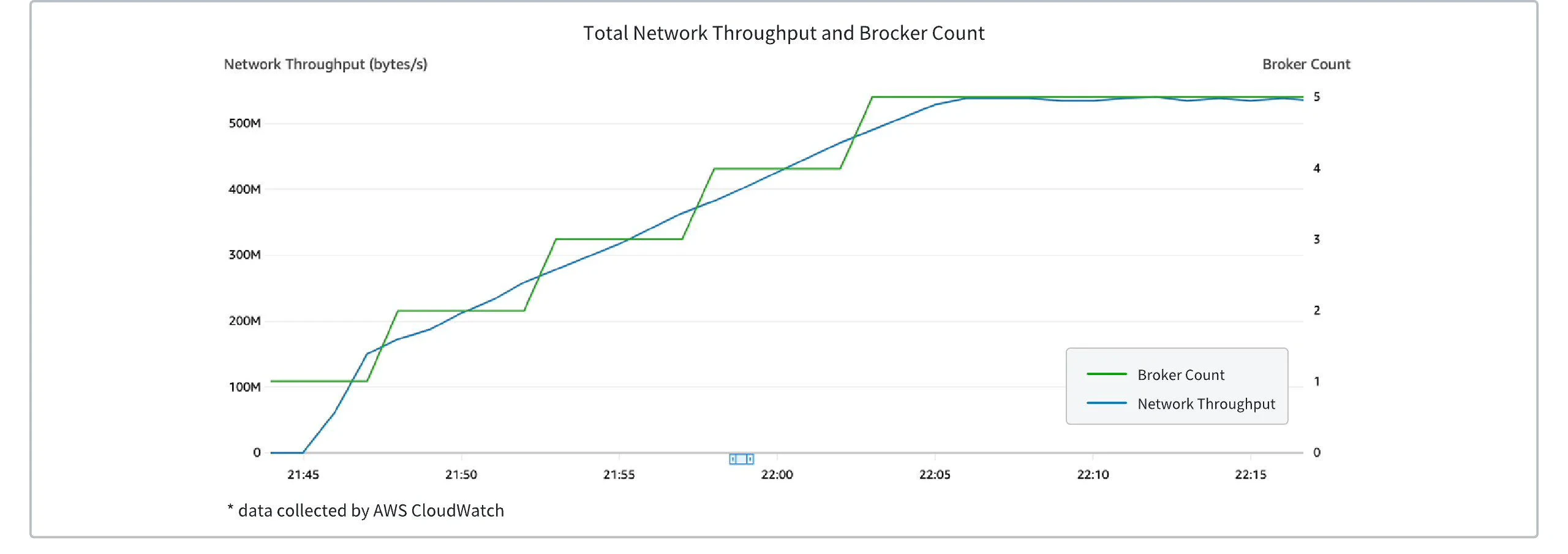
Triggering Scale Down
Taking AWS Auto Scaling Groups as an example, when the cluster traffic reaches the scale-down threshold, the Broker node to be scaled down will undergo a graceful shutdown process. During this time, the partitions on the Broker will be reassigned in a round-robin manner to the remaining Brokers within seconds, completing the graceful shutdown and traffic transfer. The figure below shows the change in the number of Brokers in an AutoMQ Kafka cluster as traffic decreases. You can observe that as traffic linearly decreases, Brokers are dynamically shut down to save resources.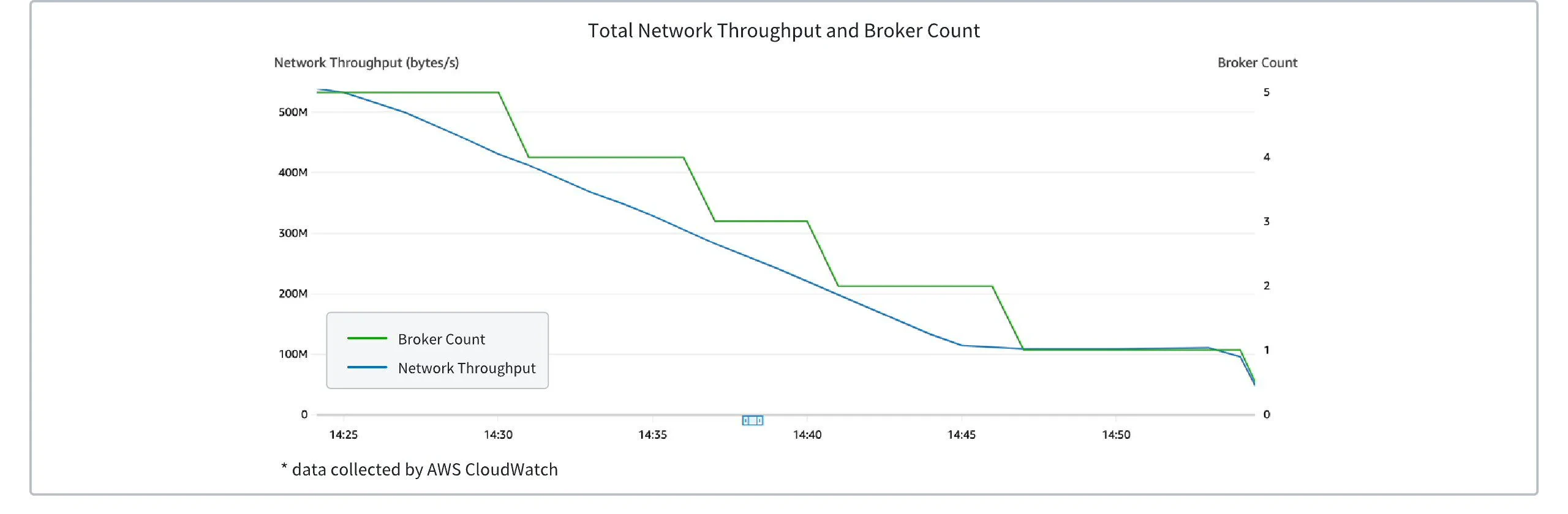
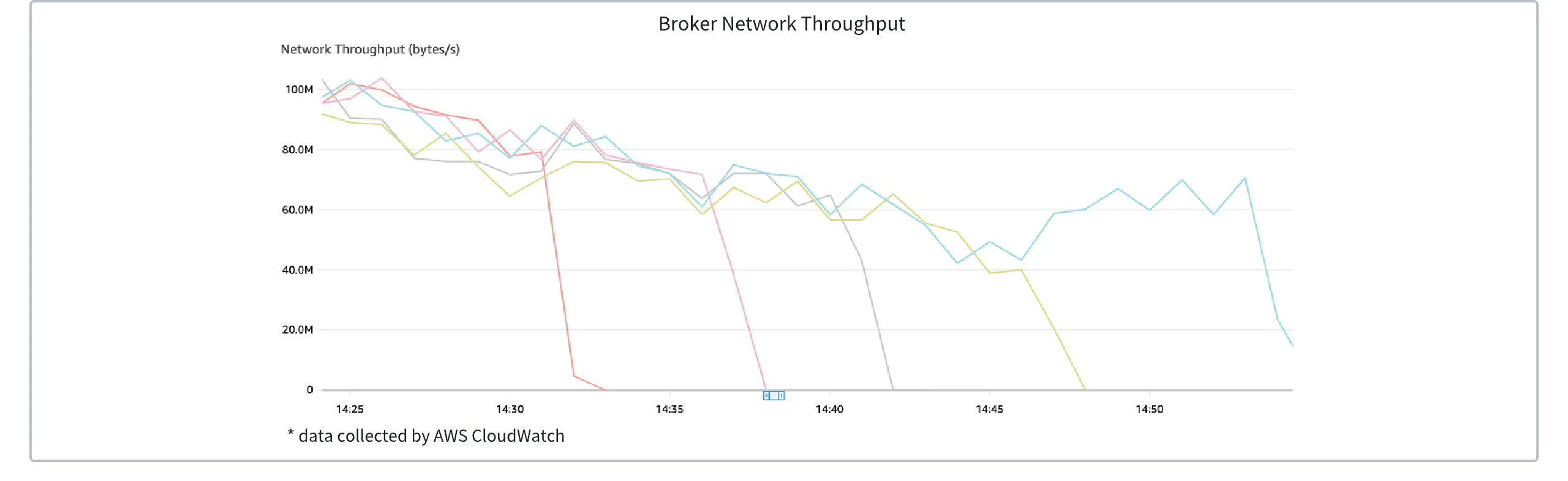
In the above example, to facilitate observation, the ASG’s scale-up and scale-down cooldown times were artificially increased, and process startup and destruction delays were added.
Advantages of Automatic Scaling
AutoMQ’s shared storage architecture inherently supports rapid automatic scaling, which is also the foundation for achieving Serverless. The automatic scaling capabilities of AutoMQ provide at least the following advantages:- Cost advantages: There is no need to prepare resources based on peak demand. Resources automatically scale according to business traffic, effectively handling tidal and burst-type workloads, with payment based on usage and no wasted idle resources.
- Stability advantages: Seamless scaling without causing additional traffic pressure on the cluster. This allows for lossless scaling even under high watermarks. In contrast, scaling in Apache Kafka® is a high-risk operation that can only be performed under low watermarks.
- Multi-tenant advantages: Clusters with automatic scaling capabilities eliminate the need to mix multiple businesses to improve resource utilization. It is entirely possible to configure an independent cluster for each business. Each independent cluster can scale according to its own traffic model. This ensures cost advantages while preventing global impact if a particular business encounters issues.