Apache Kafka Cold Read Issue
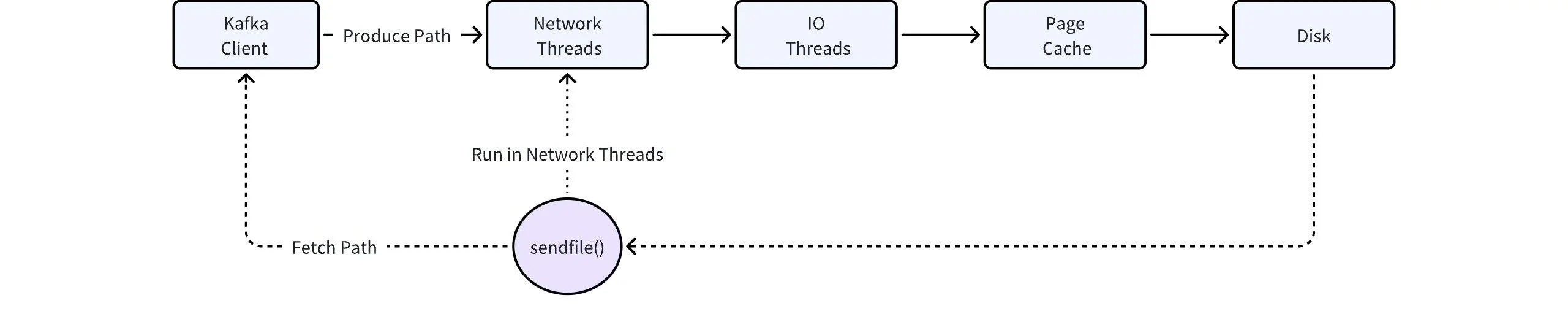
- The Page Cache greatly simplifies Kafka’s memory management burden, which is entirely handled by the kernel. However, there is an issue where hot and cold data cannot be separated. If a service continuously performs cold reads, it will compete for memory resources with hot data, leading to a continuous decline in tail read capabilities.
- SendFile is a critical technology for Kafka’s zero-copy feature, but this call occurs in Kafka’s network thread pool. If SendFile needs to copy data from the disk (in a cold read scenario), it will partially block this thread pool. Since this thread pool handles Kafka requests, including write requests, the blocking behavior of SendFile will significantly impact Kafka’s write operations.
AutoMQ Cold and Hot Data Isolation Architecture
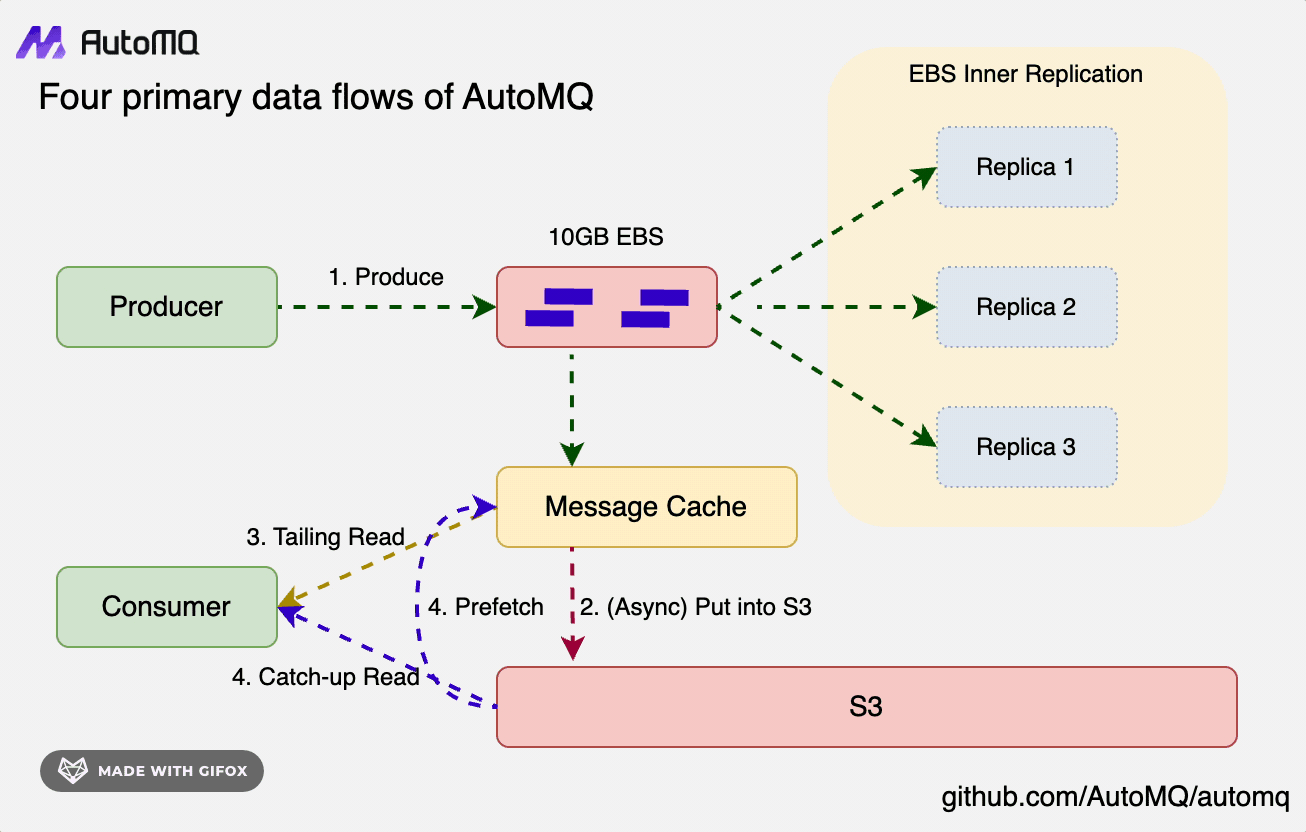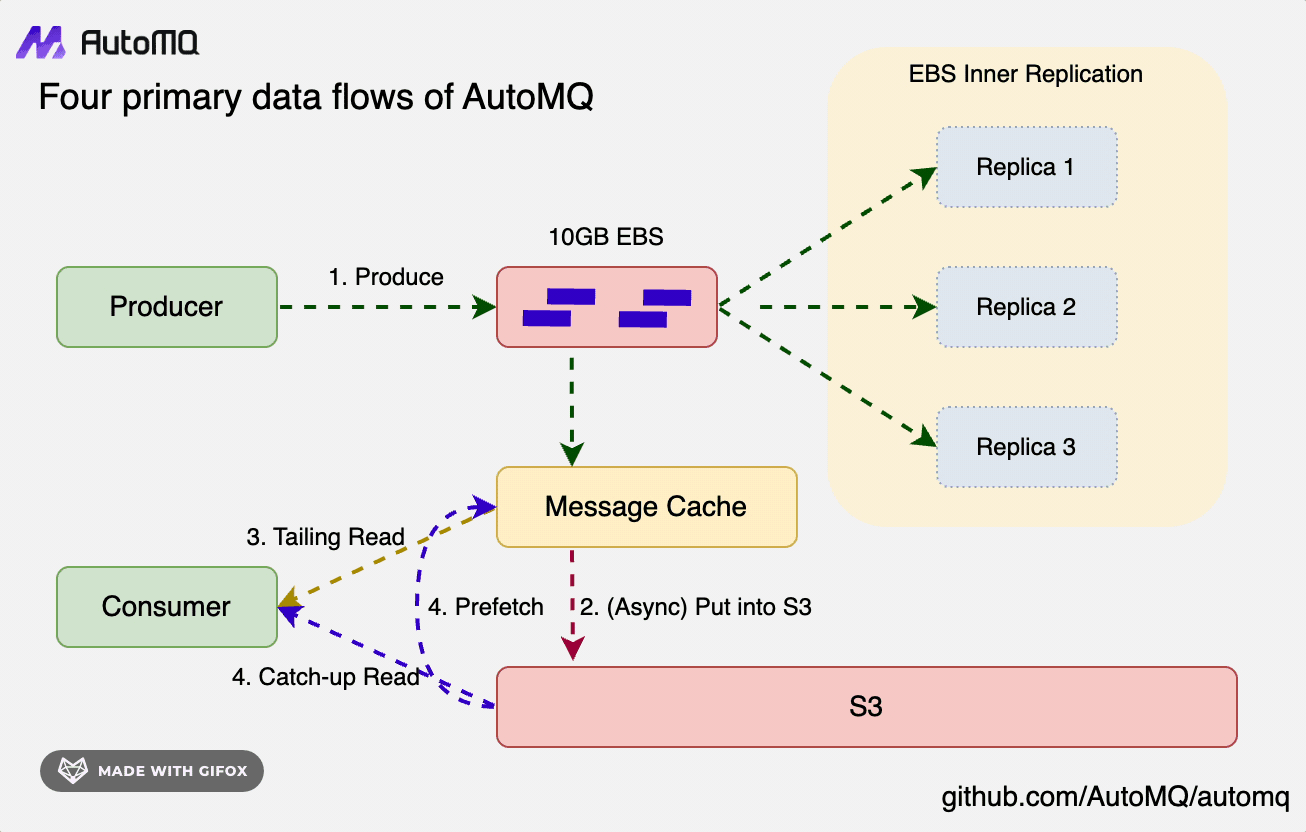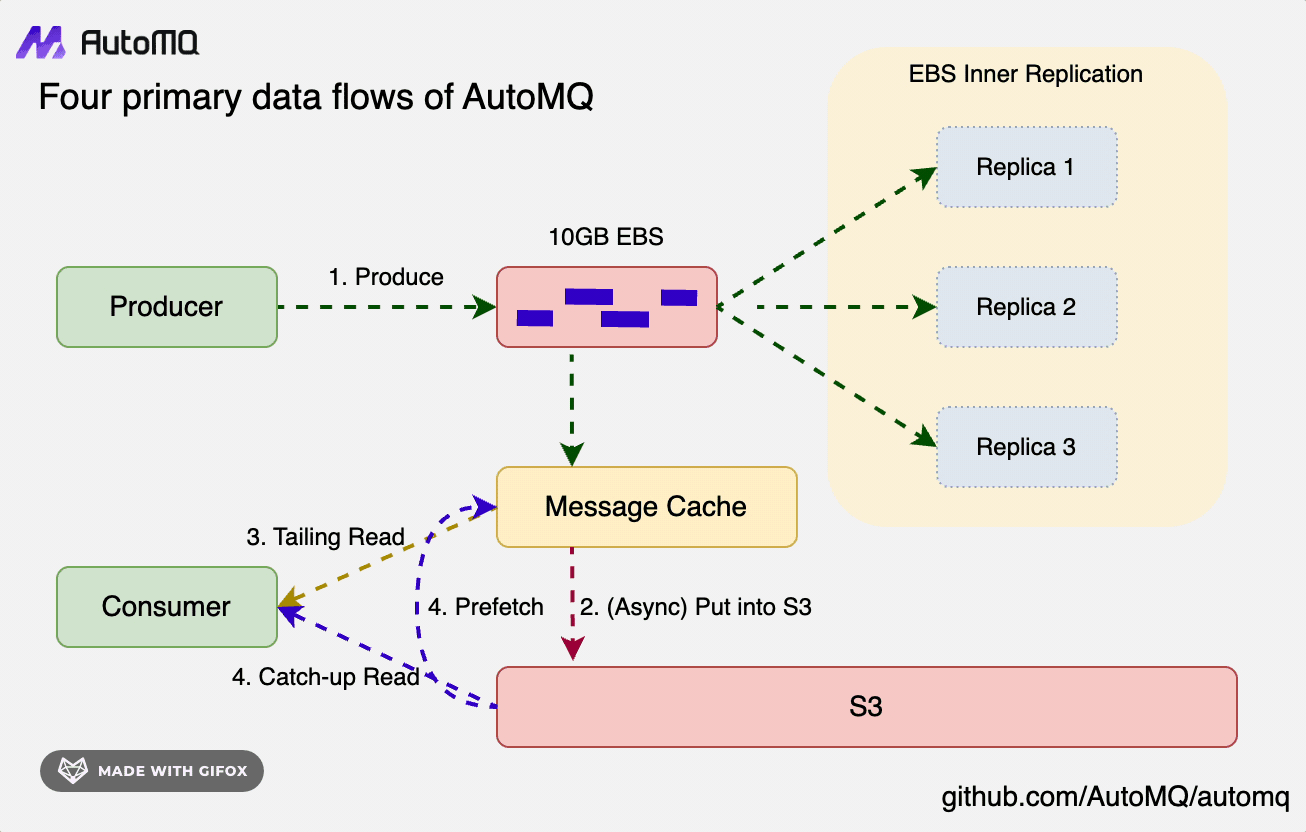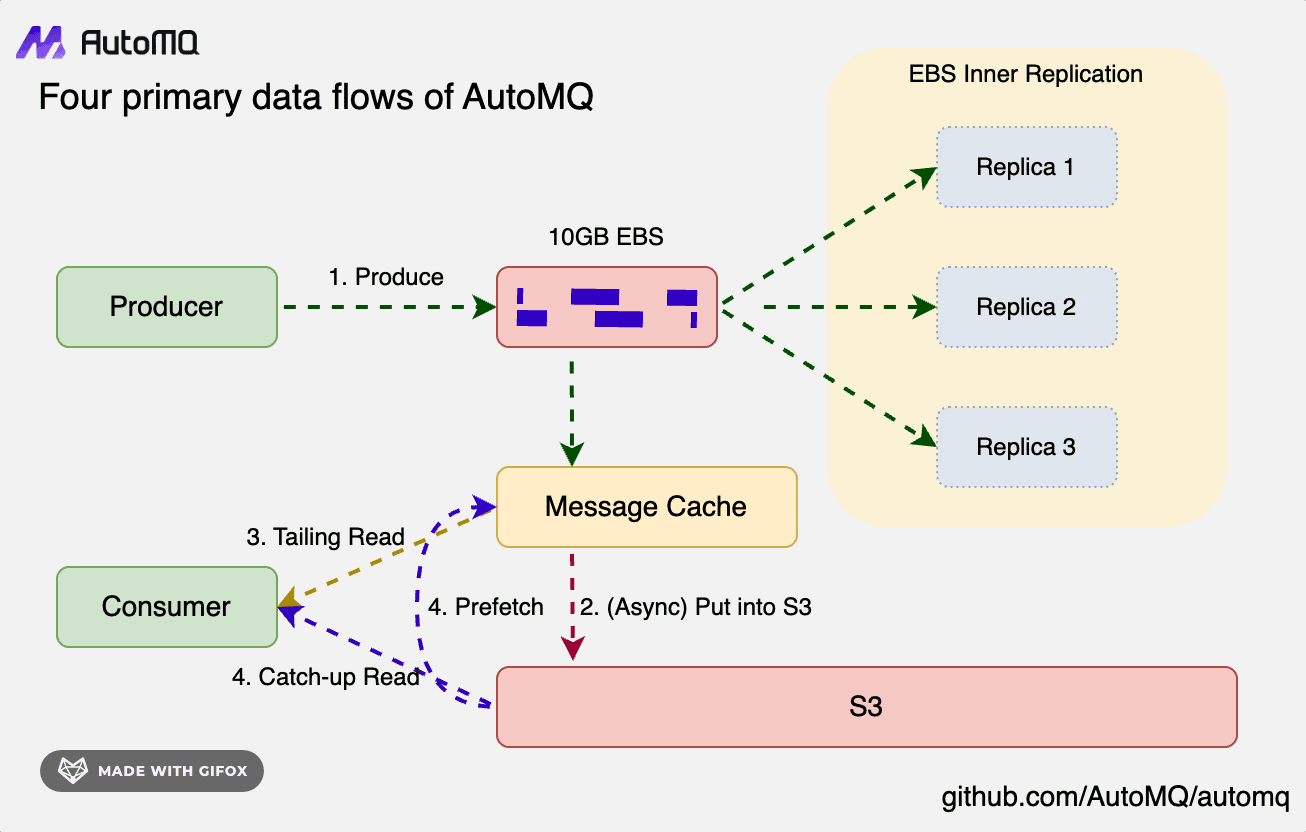
- Write Path: Data is persistently written into WAL storage in the form of Direct IO, without relying on Page Cache. The data is written through to WAL before returning success to the client, completely separating it from the data read path.
- Tail Read Path
- Cold Read Path
Cold Read Performance Evaluation of AutoMQ
The following table results are derived from the actual benchmark of AutoMQ vs. Kafka (Benchmark: AutoMQ vs. Apache Kafka▸), demonstrating that under the same load and machine types, AutoMQ maintains the same level of cold read performance as Kafka without affecting write throughput and latency.| Comparison Item | Send Latency During Cold Read | Impact on Send Traffic During Cold Read | Cold Read Efficiency (Time to Read 4TiB Data) |
|---|---|---|---|
| AutoMQ | Less than 3ms | Read-write isolation, maintains 800 MiB/s | 42 minutes |
| Apache Kafka | Approximately 800ms | Mutual impact, drops to 150 MiB/s | 215 minutes |