Apache Kafka 冷读问题
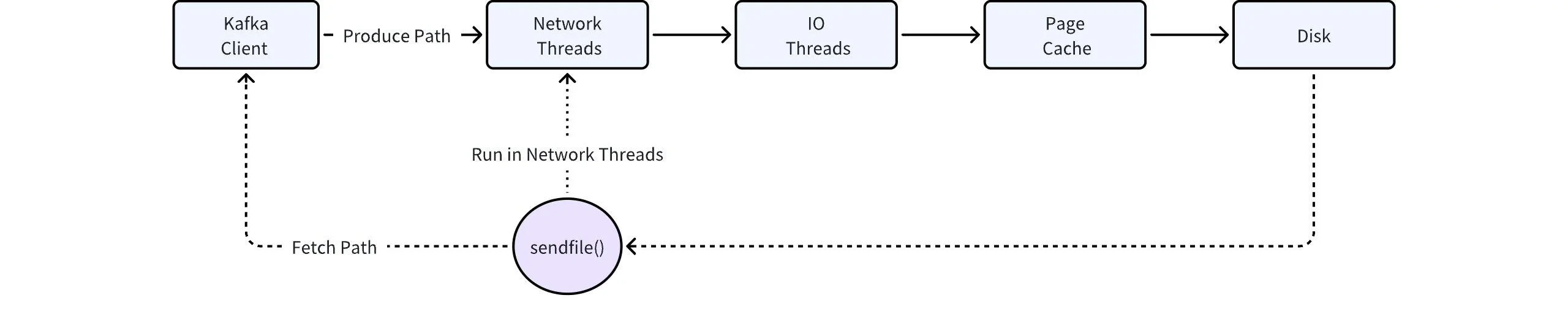
- Page Cache 极大地简化了 Kafka 内存管理的负担,完全由内核来负责。但存在冷热无法分离的问题,如果有业务持续在冷读,会跟热数据互相争抢内存资源,导致追尾读能力持续下降。
- SendFile 是 Kafka 零拷贝的关键技术,但该调用行为发生在 Kafka 的网络线程池,如果执行 SendFile 时需要从磁盘上拷贝数据(冷读场景),会在一定程度上阻塞该线程池。又因为该线程池是处理 Kafka 请求的入口,包括写请求,SendFile 的阻塞行为将导致 Kafka 的写入受到巨大的影响。
AutoMQ 冷热隔离架构
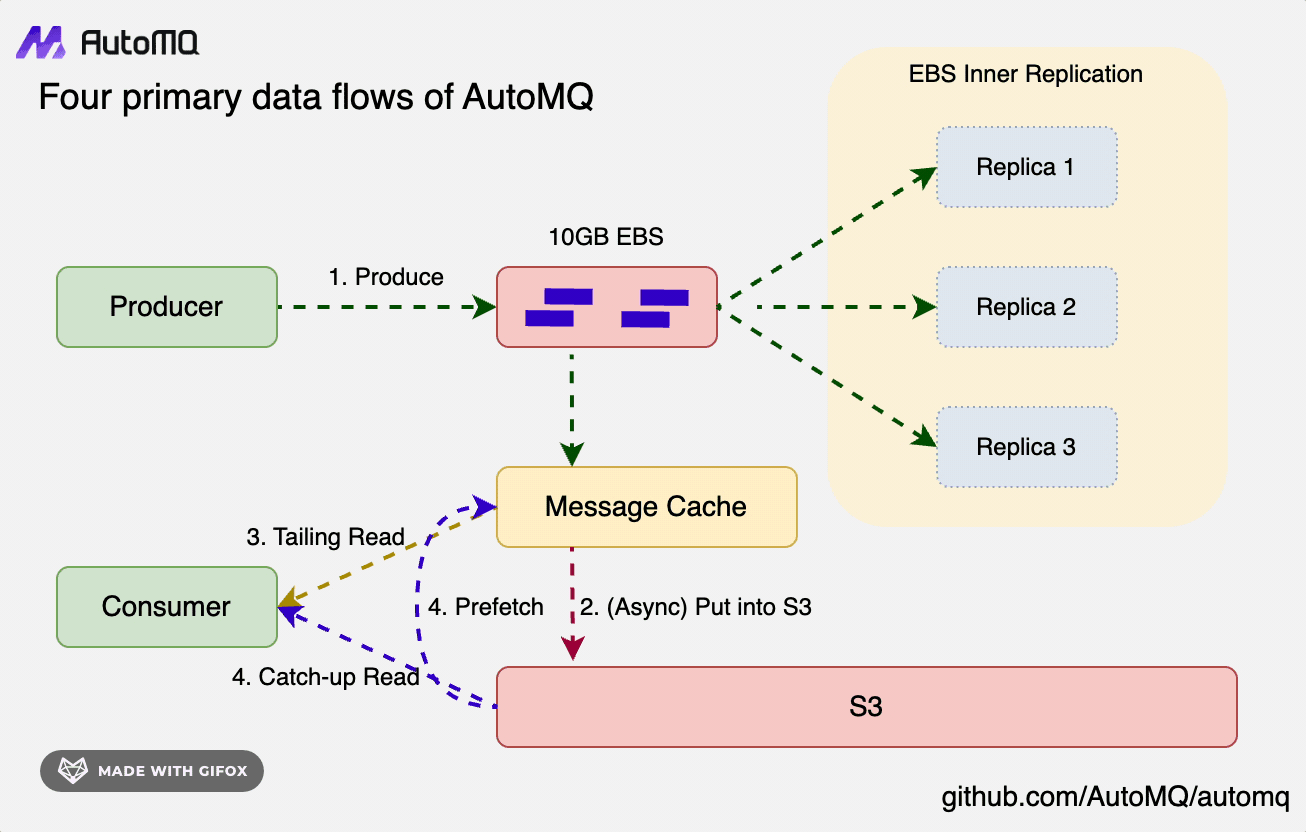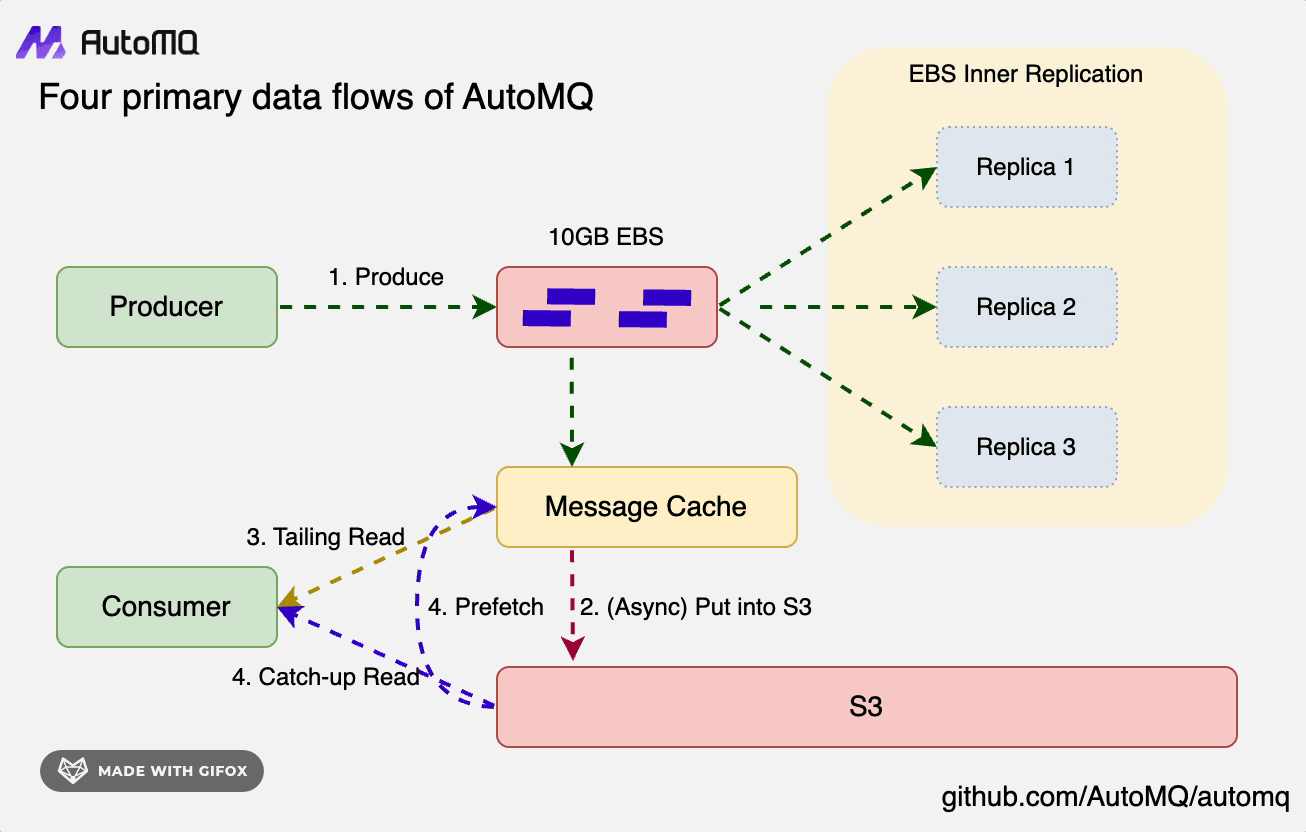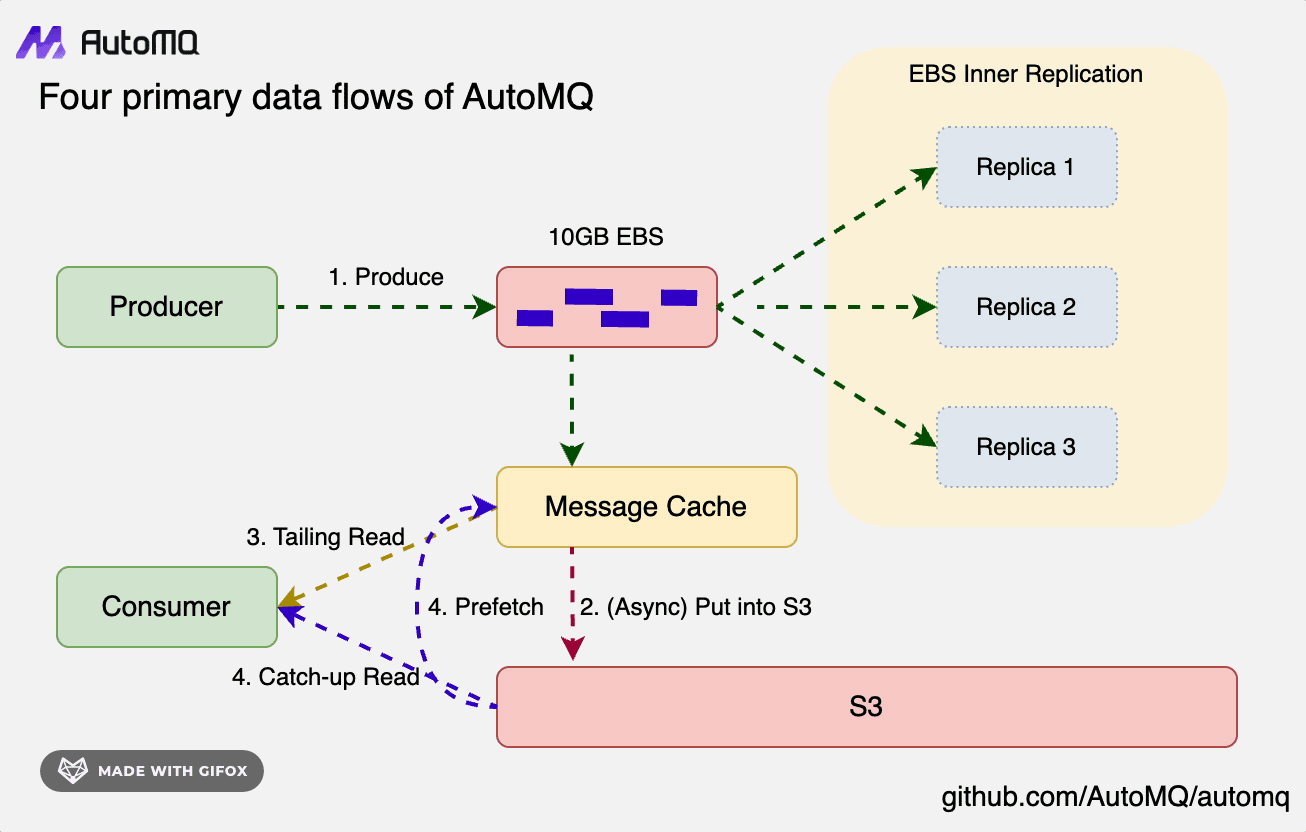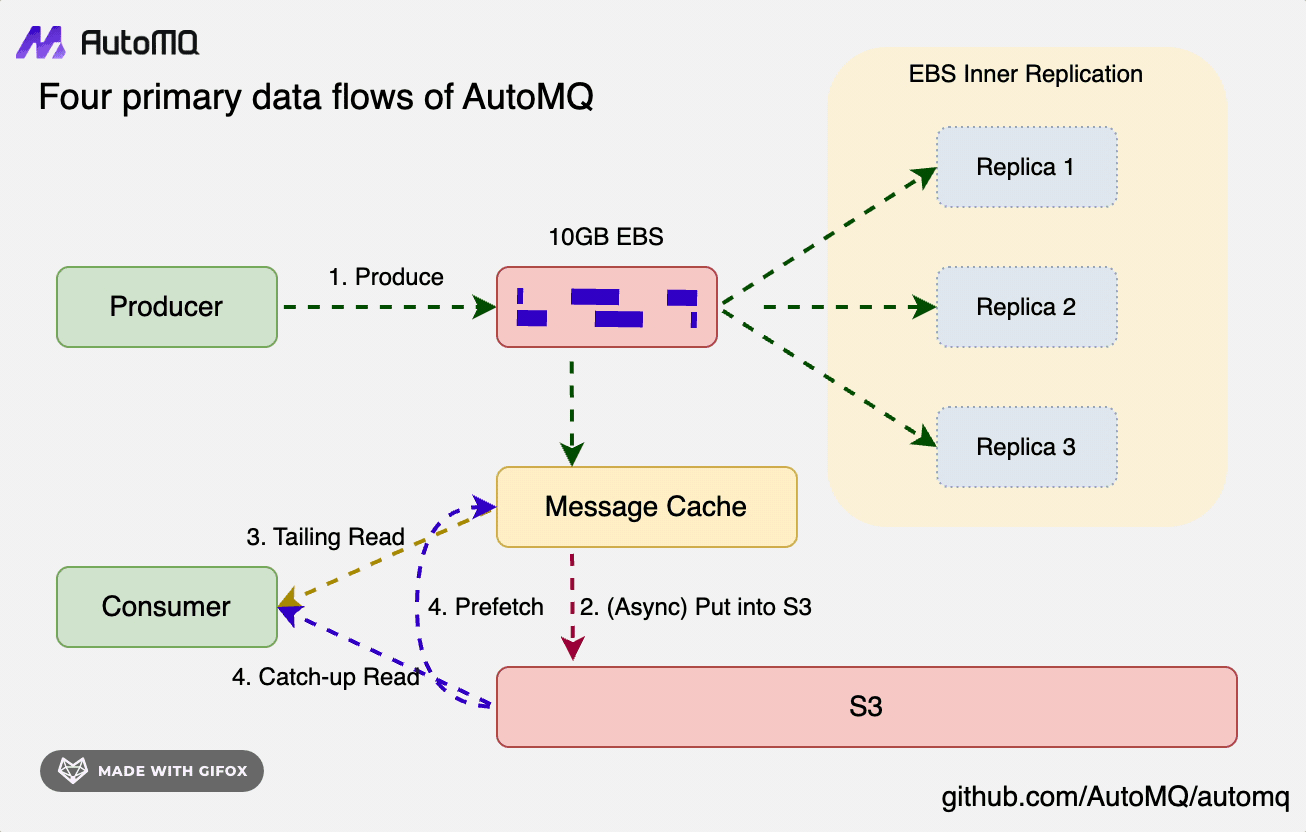
- 写入链路:数据以 Direct IO 的形式持久化写入到 WAL 存储当中,该过程不会依赖 Page Cache,数据写穿到 WAL 即返回客户成功,跟数据的读取链路完全分开。
- 追尾读链路:对于追尾读场景,数据直接从 AutoMQ 自建的 Cache 中读取。AutoMQ 的 Cache 组件类似于 Page Cache,当对冷热数据进行了分区隔离,也会在驱逐策略中充分考虑到消费者的关注度,以提高内存的效率。
- 冷读链路:对于冷读场景,数据直接从 S3 存储中读取,并通过预读策略来构建冷读 Cache。得益于对象存储的超高吞吐,以及冷热隔离的机制,AutoMQ 在冷读效率方面相较于 Apache Kafka 有数倍的提升。
AutoMQ 冷读性能评测
以下表格的结果来自于 AutoMQ vs Kafka 的实测(AutoMQ vs. Apache Kafka 性能对比▸),显示在相同负载和机型下相比 Kafka,AutoMQ 冷读时可以保证不影响写入吞吐和延迟的情况下,拥有和 Kafka 相同水准的冷读性能。| 对比项 | 冷读过程中发送耗时 | 冷读过程中对发送流量影响 | 冷读效率 (冷读 4TiB 数据耗时) |
|---|---|---|---|
| AutoMQ | 小于 3ms | 读写隔离,维持 800 MiB/s | 42 分钟 |
| Apache Kafka | 大约 800ms | 相互影响,下跌到 150 MiB/s | 215 分钟 |