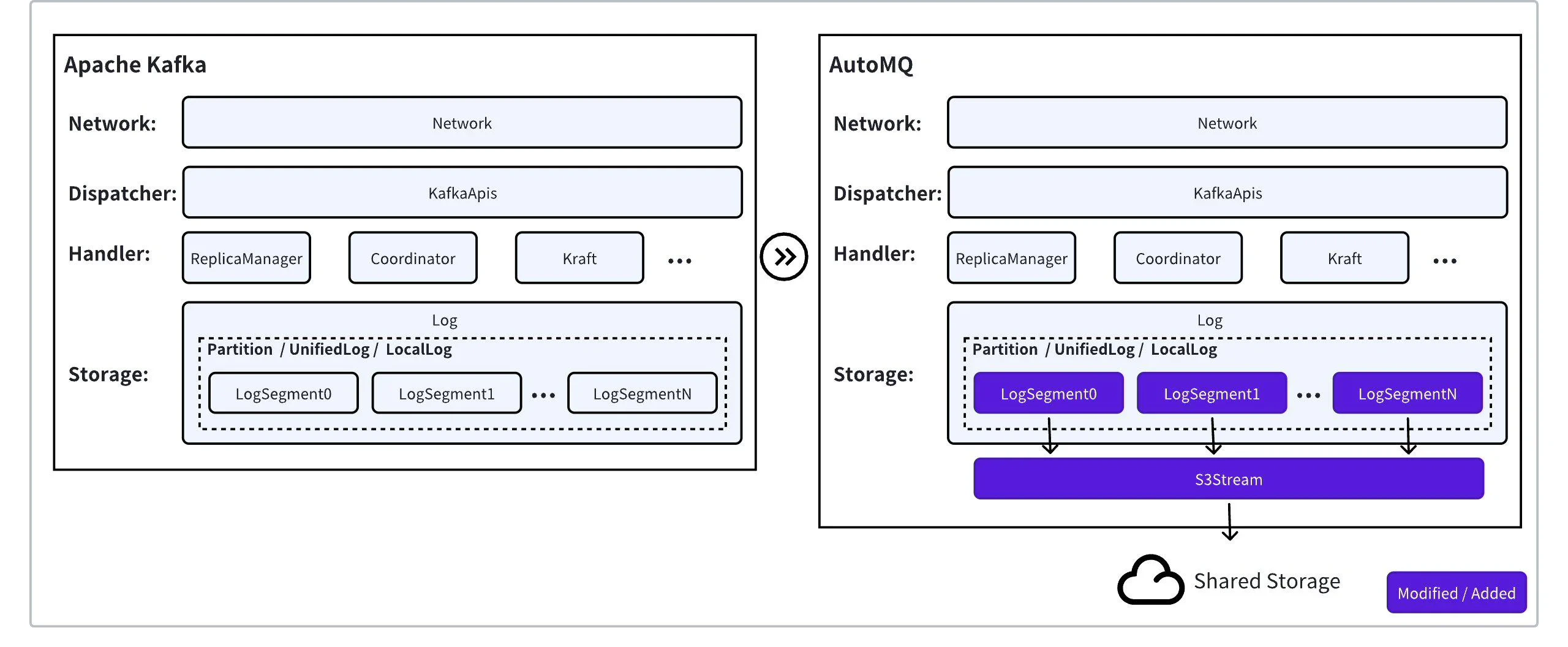
Apache Kafka 协议现状
Apache Kafka 已经经过 10 多余年的发展,由 1000+ Contributors 共同贡献了 1059 个 KIP[1],整个代码库包含数十万行代码,沉淀了大量的功能特性、优化和修复。如果要从零开始构建一个 API 协议和语义兼容的 Kafka 不仅开发工作量大,并且极易出错。Apache Kafka 架构由计算层和存储层构成:- 计算层:代码总量的 98%,承载了 Kafka 的 API 协议和功能特性。同时,计算层面向流存储有大量的系统性优化,比如端到端的 Batch 设计,零拷贝机制等,通过 2 核 CPU 就能支撑 1GiB/s 的流量;
- 存储层:代码总量的 2%,负责消息的高可靠存储。Apache Kafka 作为流处理管道会长期存储大量数据,Apache Kafka 集群成本的大部分是由数据存储成本和存算一体部署的机器成本组成。
AutoMQ 原生支持 Kafka 协议
AutoMQ 的目标是通过存算分离的架构将 Apache Kafka 升级为共享存储的架构,最优的解决方案就是替换 Kafka 的存储层,保留 Kafka 原生的计算层,这样做的优势在于:- 既可以复用 98% Apache Kafka 计算层代码,保障 API 的协议 & 语义兼容和功能对齐;
- 又可以将存储层替换为云原生的存储服务,兑现共享存储和云原生的技术和成本红利。