AutoMQ 如何实现秒级分区迁移
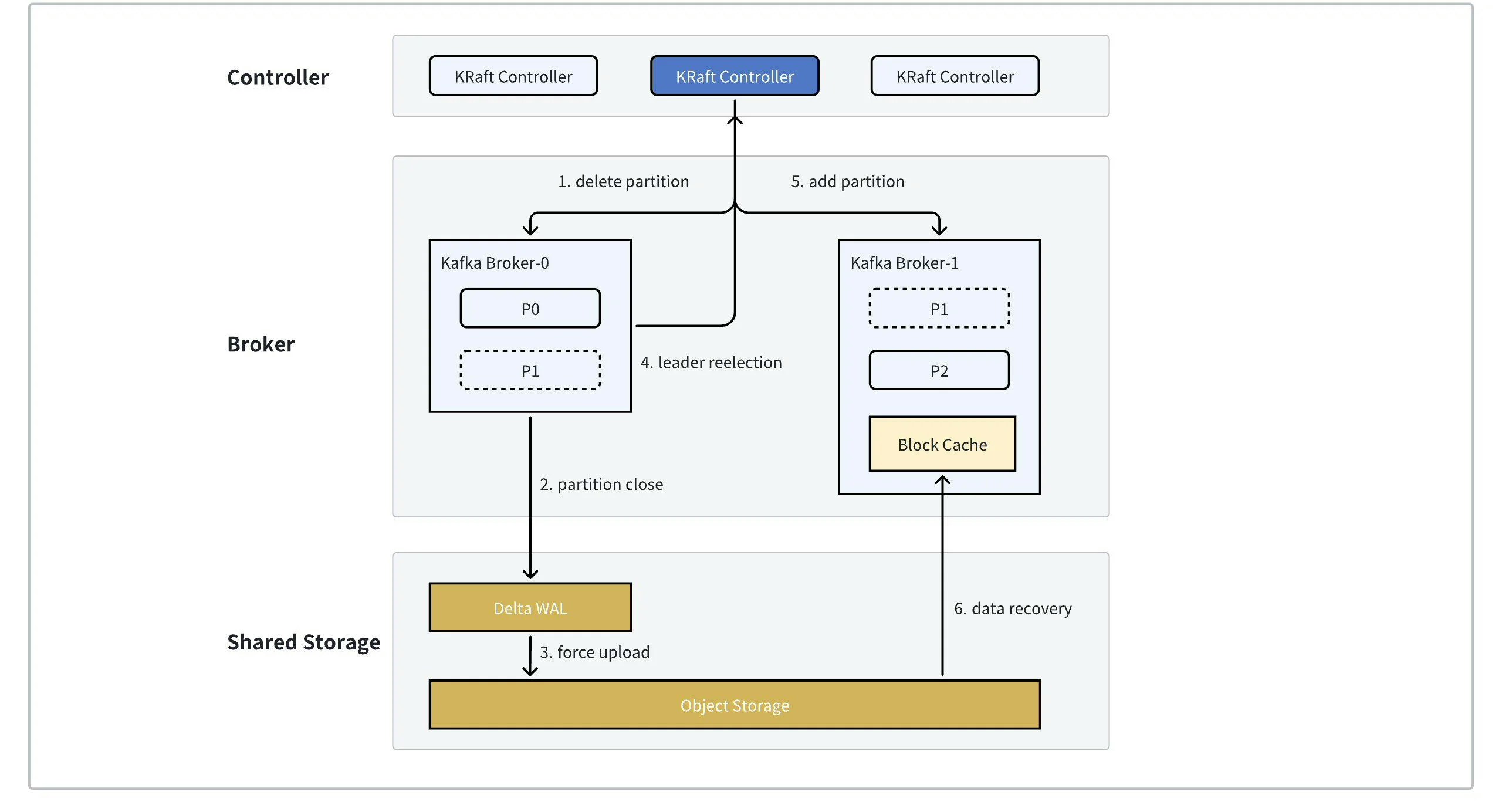
- 当 KRaft Controller 收到分区迁移命令时,会构建出相应的 PartitionChangeRecord 并 Commit 至 KRaft Log 层,将 Broker-0 从 Leader Replica 列表中删除,并将 Broker-1 加入 Follower Replica 列表中。Broker-0 同步 KRaft Log 监听到 P1 分区变更,进入分区关闭流程。
- 分区关闭时,若 P1 还存在未上传至对象存储的数据,则会触发强制上传,而在一个稳定运行的集群中,这部分数据往往在百 MB左右,结合目前云厂商提供的突发网络带宽能力,这个过程一般仅需秒级即可完成。当 P1 的数据上传完成后,即可安全的关闭并从 Broker-0 删除分区 P1。
- P1 从 Broker 完成关闭后会主动触发一次选主,此时 Broker-1 作为唯一的 Replica 晋升为 P1 的 Leader,进入分区恢复流程。
- 分区恢复时,会从对象存储中拉取 P1 对应的元数据,从而恢复出 P1 相应的 Checkpoint,后根据 P1 的关闭状态(是否为 Cleaned Shutdown)进行对应的数据恢复。
- 至此分区迁移完成。
秒级分区迁移的意义
在生产环境中,一个 Kafka 集群通常会服务多个业务,业务的流量波动和分区分布可能造成集群容量不足或者机器热点,Kafka 运维人员需要通过集群扩容,并且将热点分区迁移到空闲的节点,来保障集群的服务可用性。 分区迁移的时间决定了应急和运维效率:- 分区迁移的时间越短,集群从扩容到容量满足诉求的时间越短,服务受损的时间越短。
- 分区迁移越快,运维人员观测的时间更短,可以更快的得到运维反馈决策后续的动作。