Scale-out/in in Seconds
In the cloud-native era, leveraging the elasticity capabilities provided by cloud providers, we have been able to achieve node-level scaling of online clusters effectively. For example, AWS's Auto Scaling Groups and Alibaba Cloud's ESS Elastic Scaling Groups. However, due to the involvement of business traffic reassignment, Apache Kafka® clusters often cannot directly utilize the elasticity capabilities provided by cloud providers. Instead, manual intervention by operations personnel is required to shuffle the traffic, which usually takes hours. For online clusters with frequent traffic fluctuations, it is almost impossible to achieve on-demand scaling. To ensure cluster stability, operations personnel can only pre-deploy according to the maximum capacity to avoid the risk of delayed scaling during traffic peaks. This leads to significant resource waste.
How AutoMQ Achieves Second-Level Smooth Scaling
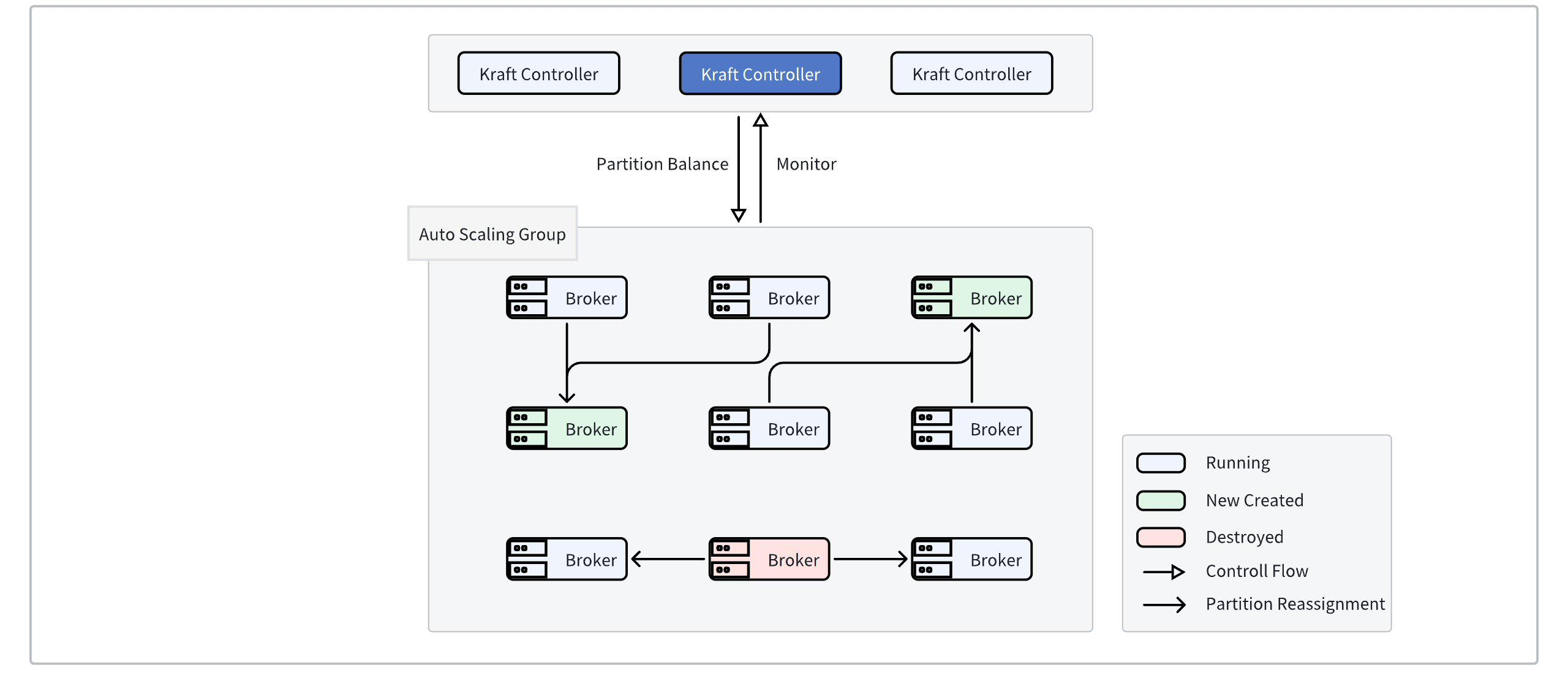
The second-level scaling feature of AutoMQ relies on an atomic capability, namely second-level partition reassignment (refer to Partition Reassignment in Seconds▸).
When leveraging Auto Scaling Groups (ASG) or Kubernetes' HPA to complete node scaling, you only need to migrate some partitions in the cluster to the new nodes in batches to achieve traffic self-balancing (refer to Continuous Self-Balancing▸). This process can often be completed within ten seconds.
Triggering Scaling
Taking AWS Auto Scaling Groups (ASG) as an example, by configuring traffic threshold monitoring, new broker nodes are automatically initiated when the cluster traffic reaches the scaling threshold. At this time, the Controller detects the traffic imbalance and automatically moves partitions to the newly created brokers, achieving rebalanced traffic distribution.
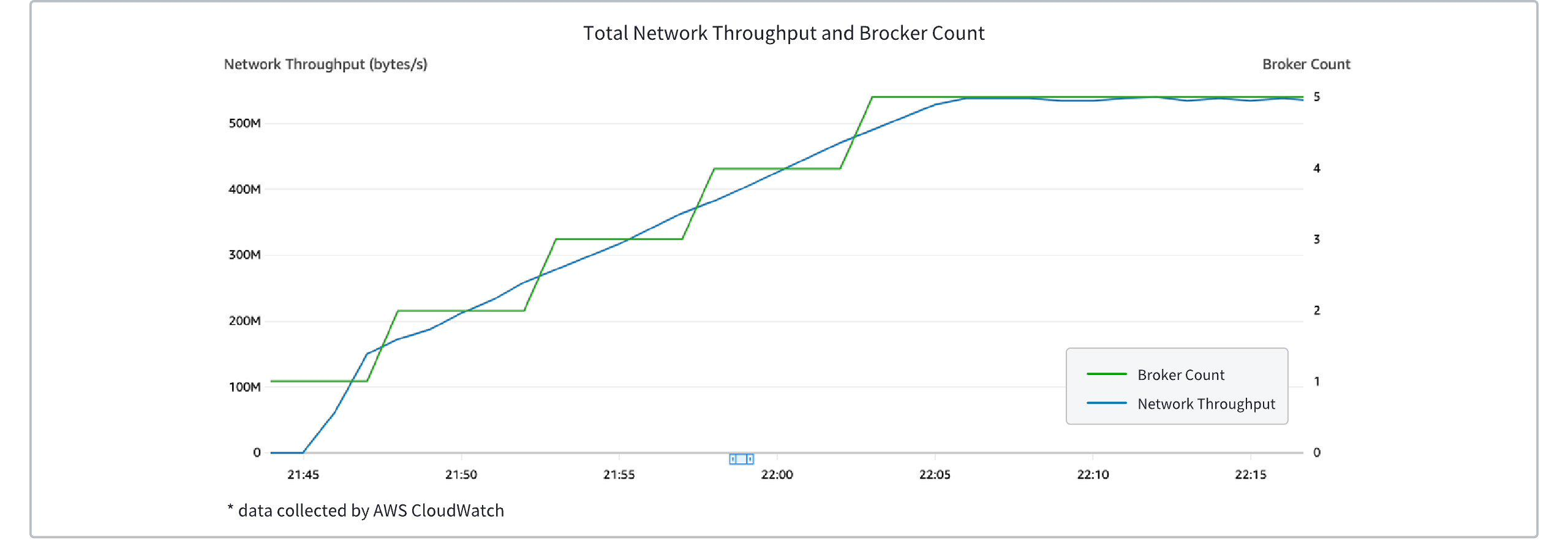
The following diagram shows the change in the number of brokers in an AutoMQ Kafka cluster as traffic increases. It can be seen that as traffic linearly rises, brokers are dynamically created and added to the cluster to balance the load.
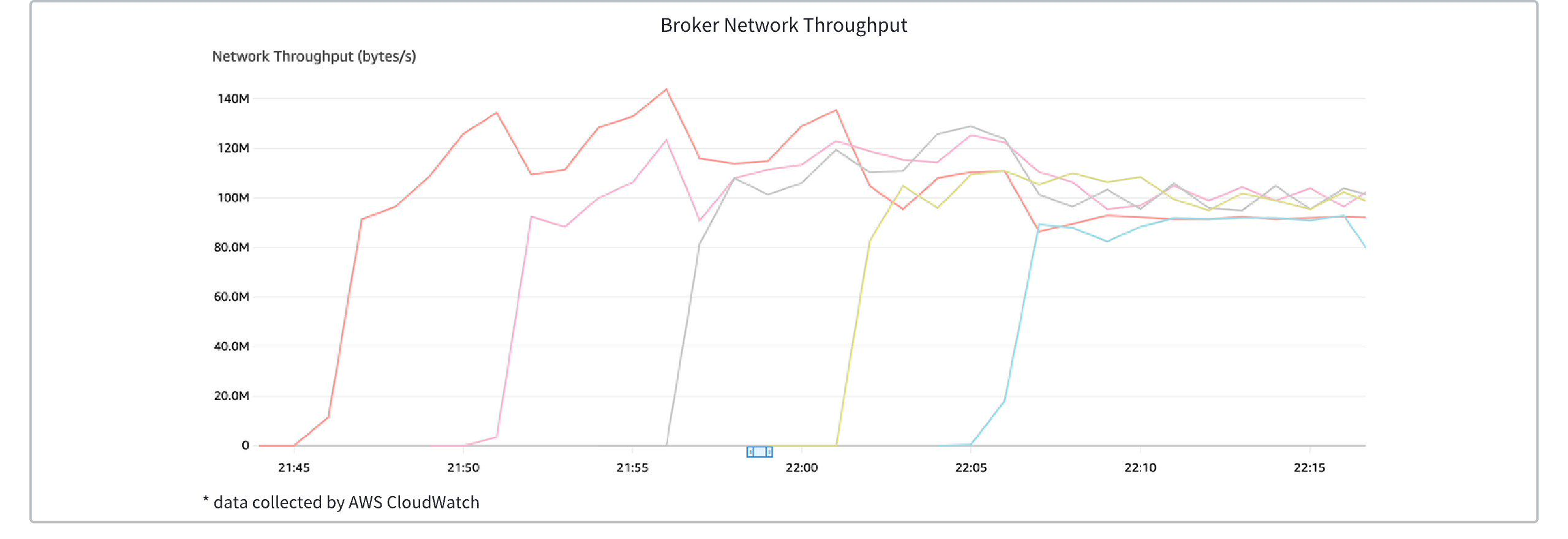
The diagram below illustrates the traffic changes across broker nodes during traffic spikes. It can be observed that the newly created brokers complete traffic rebalancing within seconds.
Triggering Scale-Down
Using AWS Auto Scaling Groups as an example, when the cluster traffic hits the scale-down threshold, the broker nodes that are about to be scaled down will be decommissioned. At this time, the partitions on these brokers will be reassigned to the remaining brokers in a round-robin manner within seconds, completing the graceful shutdown of the broker and traffic transfer.
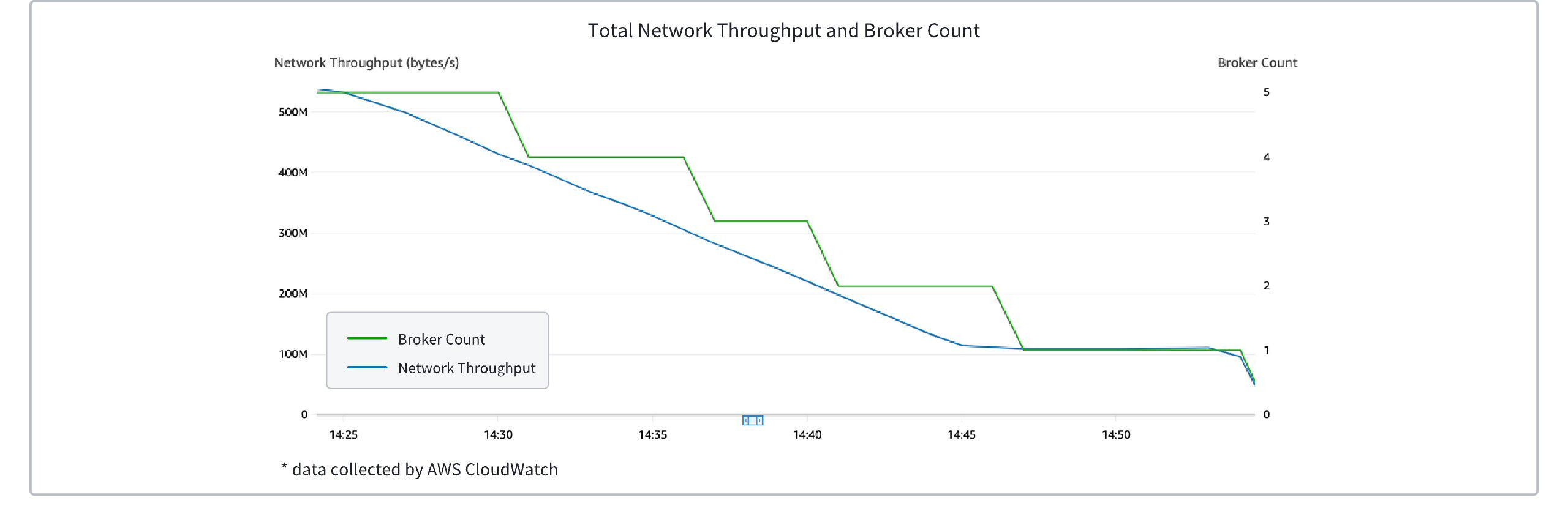
The figure below shows the change in the number of brokers in an AutoMQ Kafka cluster as traffic decreases. It can be seen that brokers are dynamically decommissioned as traffic decreases linearly, thereby conserving resources.
The figure below illustrates the traffic changes for each broker node during traffic decline. It can be observed that the load on the decommissioning brokers is transferred to the remaining brokers (whenever a broker is decommissioned, a significant increase in traffic on the other brokers can be observed).
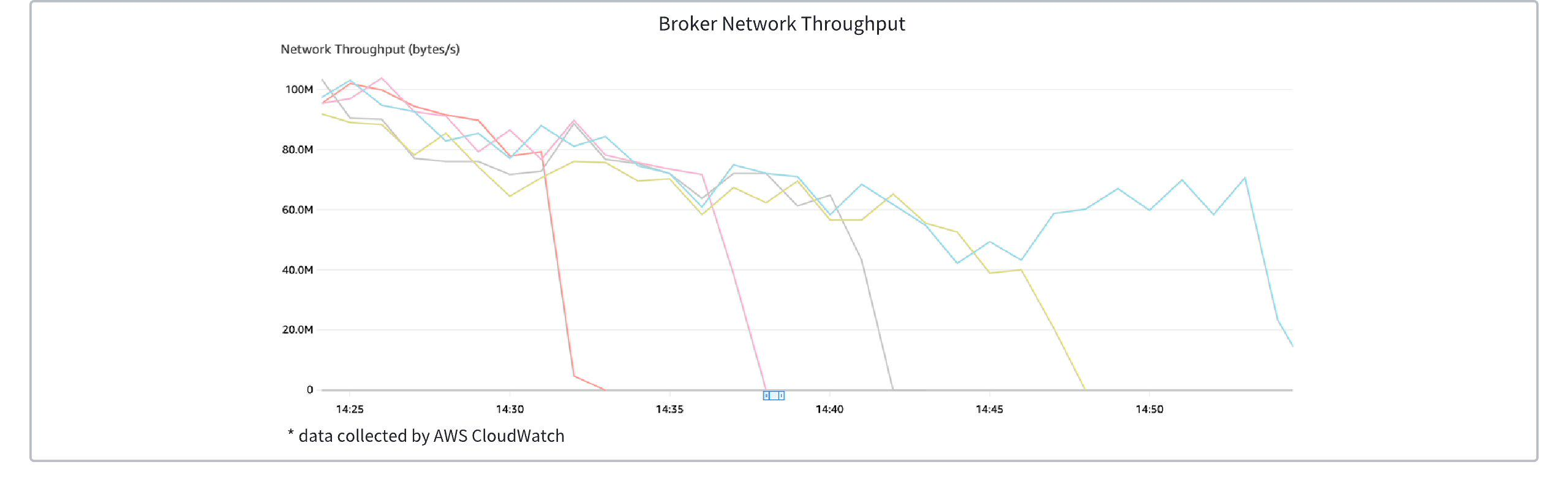
In the above example, to facilitate observation, the cooling time for the ASG node scaling actions was artificially increased, and the process startup and shutdown delays were added.
Advantages of Automatic Scaling
AutoMQ's shared storage architecture naturally supports rapid automatic scaling, which is also the basis for achieving serverless functionality. AutoMQ supports automatic scaling with at least the following advantages:
Cost advantages: There is no need to prepare resources based on peak demand. Resources automatically scale according to business traffic, effectively handling tidal and burst traffic patterns, and charging based on the area used without any resource wastage.
Stability Advantage: The expansion process does not add extra traffic pressure on the cluster, allowing for non-disruptive scaling even under high watermark conditions. In contrast, expanding Apache Kafka is a high-risk operation that can only be performed under low watermark conditions.
Multi-Tenancy Advantage: Clusters with auto-scaling capabilities eliminate the need to mix workloads to improve resource utilization. Instead, an independent cluster can be configured for each business, which can scale independently according to its traffic model. This ensures cost advantages while avoiding global impacts when a single business encounters issues.
References
[1]. AWS Auto Scaling Groups: https://docs.aws.amazon.com/autoscaling/ec2/userguide/auto-scaling-groups.html
[2]. Alibaba Cloud ESS Elastic Scaling Group: https://www.aliyun.com/product/ecs/ess
[3]. Kubernetes HPA Component for Scaling: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/