Native Compatible with Apache Kafka
Currently, there are many products in the industry that support the Apache Kafka® protocol, such as Redpanda and Kafka on Pulsar. AutoMQ believes that starting from scratch to adapt to the Kafka protocol is extremely challenging to achieve complete compatibility in every detail, and it also entails a significant amount of repetitive and unnecessary intellectual work.
At present, the Kafka protocol includes 113 ErrorCodes and 68 APIs, with the Fetch API alone having 15 versions. Achieving 100% compatibility with Kafka's protocol and semantics is extremely difficult. Moreover, as Apache Kafka® evolves, maintaining ongoing compatibility with the Kafka protocol is also a major challenge.
Compatibility with Kafka's protocol and semantics is a critical consideration for users when choosing Kafka products. Therefore, the premise of AutoMQ's architectural design is to ensure 100% compatibility with the Apache Kafka® protocol and semantics and to continuously align with Apache Kafka®.
Current State of the Apache Kafka® Protocol
Apache Kafka® has been developed for over a decade, with contributions from over 1,000 contributors who have collectively developed 1,059 KIPs [1]. The entire codebase contains hundreds of thousands of lines of code, encompassing a vast array of features, optimizations, and fixes. Starting from scratch to build a Kafka API protocol and semantic-compatible system would not only be a massive development effort but also prone to errors. The Apache Kafka® architecture comprises a compute layer and a storage layer:
Compute Layer: Accounting for 98% of the codebase, it carries the Kafka API protocol and feature set. Additionally, the compute layer includes numerous systemic optimizations for stream storage, such as end-to-end batch design and zero-copy mechanisms, enabling support for 1GiB/s traffic with just 2 CPU cores.
Storage Layer: Comprising 2% of the codebase, it is responsible for the highly reliable storage of messages. As a stream processing pipeline, Apache Kafka® stores large amounts of data over long periods. The primary cost drivers for an Apache Kafka® cluster are data storage costs and the cost of machines deployed for integrated compute and storage.
AutoMQ Natively Supports the Kafka Protocol
AutoMQ aims to upgrade Apache Kafka® to a shared storage architecture through a compute-storage separation model. The optimal solution is to replace Kafka's storage layer while retaining its native compute layer. The advantages of this approach are:
It allows for the reuse of 98% of Apache Kafka's compute layer code, ensuring API protocol and semantic compatibility as well as feature alignment.
Additionally, it enables the storage layer to be replaced with cloud-native storage services, leveraging the technological and cost benefits of shared storage and cloud-native architectures.
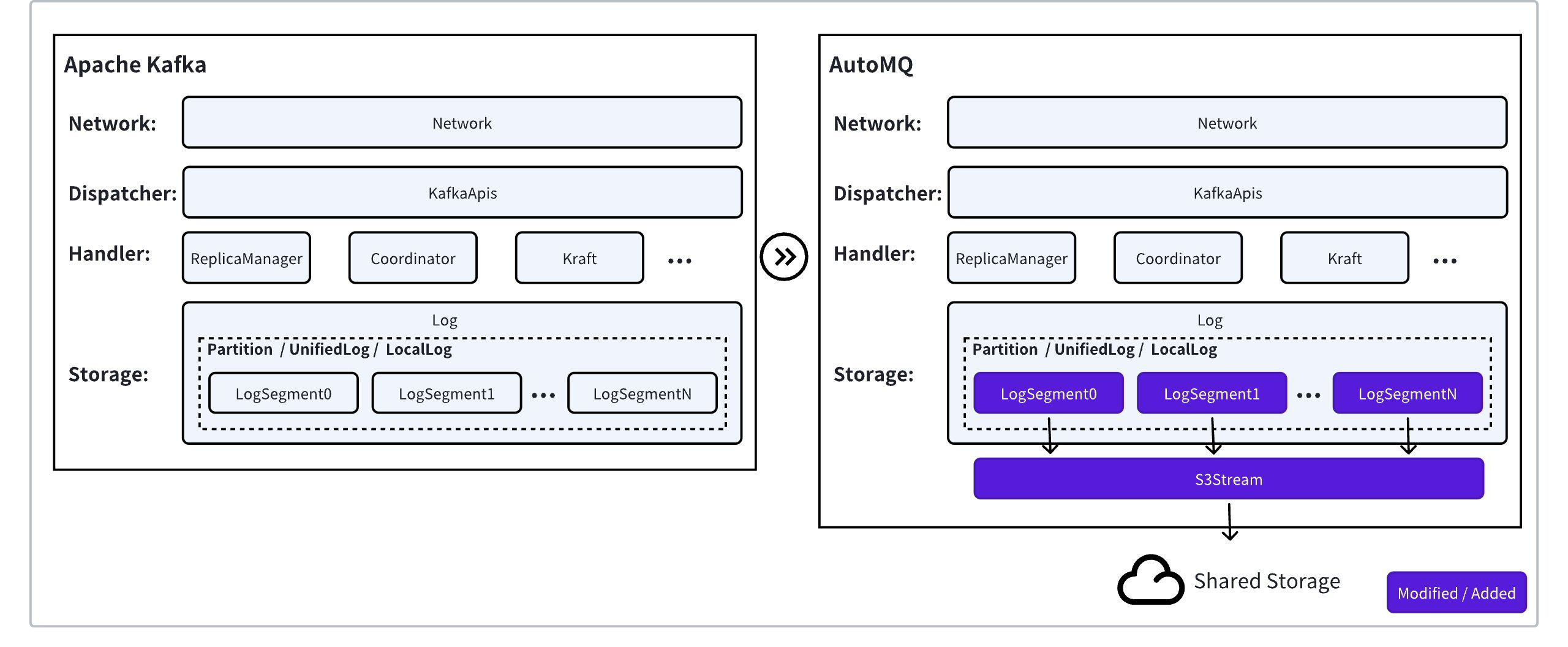
Although Apache Kafka® exposes a stream abstraction modeled by Partitions to the business logic layer, its internal Log recovery, transactional indexing, timestamp indexing, and reads are all based on Log Segments. In other words, Log Segments are the smallest operational unit of Kafka storage.
Therefore, Segments are the optimal integration point for implementing AutoMQ's compute-storage separation architecture. By implementing shared Segment semantics based on S3Stream, it is possible to reuse the logic of upper-layer components such as LocalLog, LogCleaner, and Partition, thus maximizing the reuse of Apache Kafka® code.
Beyond theoretically achieving native support for the Kafka protocol through architectural design, AutoMQ has also passed over 500 system test cases for Apache Kafka® (KRaft mode). This test suite covers Kafka functionalities (Message sending and receiving, Consumer Group management, Topic Compaction, etc.), client compatibility (>= 0.9), operations (reassignment, rolling restart, etc.), Stream and Connector testing, ensuring 100% protocol and semantic compatibility of AutoMQ in practical operation.
References
[1]. Apache Kafka KIP List: https://cwiki.apache.org/confluence/display/kafka/kafka+improvement+proposals