Continuous Self-Balancing
In an online Apache Kafka® cluster, fluctuations in traffic, the creation and deletion of Topics, and the failure and startup of Brokers occur continuously. These changes can lead to an uneven distribution of traffic across the nodes in the cluster, resulting in resource wastage and business instability. At this point, it becomes necessary to actively reassign the different partitions of the Topics across the nodes to balance traffic and data.
Challenges Faced by Open Source Solutions
Apache Kafka® has long faced significant challenges in data self-balancing. The community has two solutions:
Apache Kafka® offers a partition reassignment tool, but the specific reassignment plan needs to be determined by the operations personnel. For Kafka® clusters with hundreds or even thousands of nodes, manually monitoring cluster status and creating a comprehensive partition reassignment plan is an almost impossible task.
The community also provides third-party external plugins like Cruise Control [1] to assist in generating reassignment plans. However, due to the large number of variables involved in Apache Kafka®'s data self-balancing (such as replica distribution, leader traffic distribution, and node resource utilization), and the resource contention and hours to days of time consumption caused by data synchronization during self-balancing, existing solutions are highly complex and have low decision-making timeliness. In actual implementation of data self-balancing strategies, reliance on operations personnel for review and continuous monitoring is still required, failing to truly resolve the issues brought by Apache Kafka®'s data self-balancing.
AutoMQ's Architectural Advantages
Thanks to AutoMQ's deep application of cloud-native capabilities, we have completely reimplemented Apache Kafka®'s underlying storage based on cloud object storage, upgrading from a Shared Nothing architecture to a Shared Storage architecture. This supports second-level partition reassignment capabilities. Therefore, the decision factors for partition reassignment plans are greatly simplified:
There is no need to consider the disk resources of the nodes.
No need to consider the leader distribution and replica distribution of partitions.
Partition reassignment does not involve data synchronization and copying.
Therefore, we have the opportunity to implement a built-in, lightweight data self-balancing component within AutoMQ that continuously monitors cluster status and automatically executes partition reassignment.
AutoMQ Data Self-Balancing Implementation
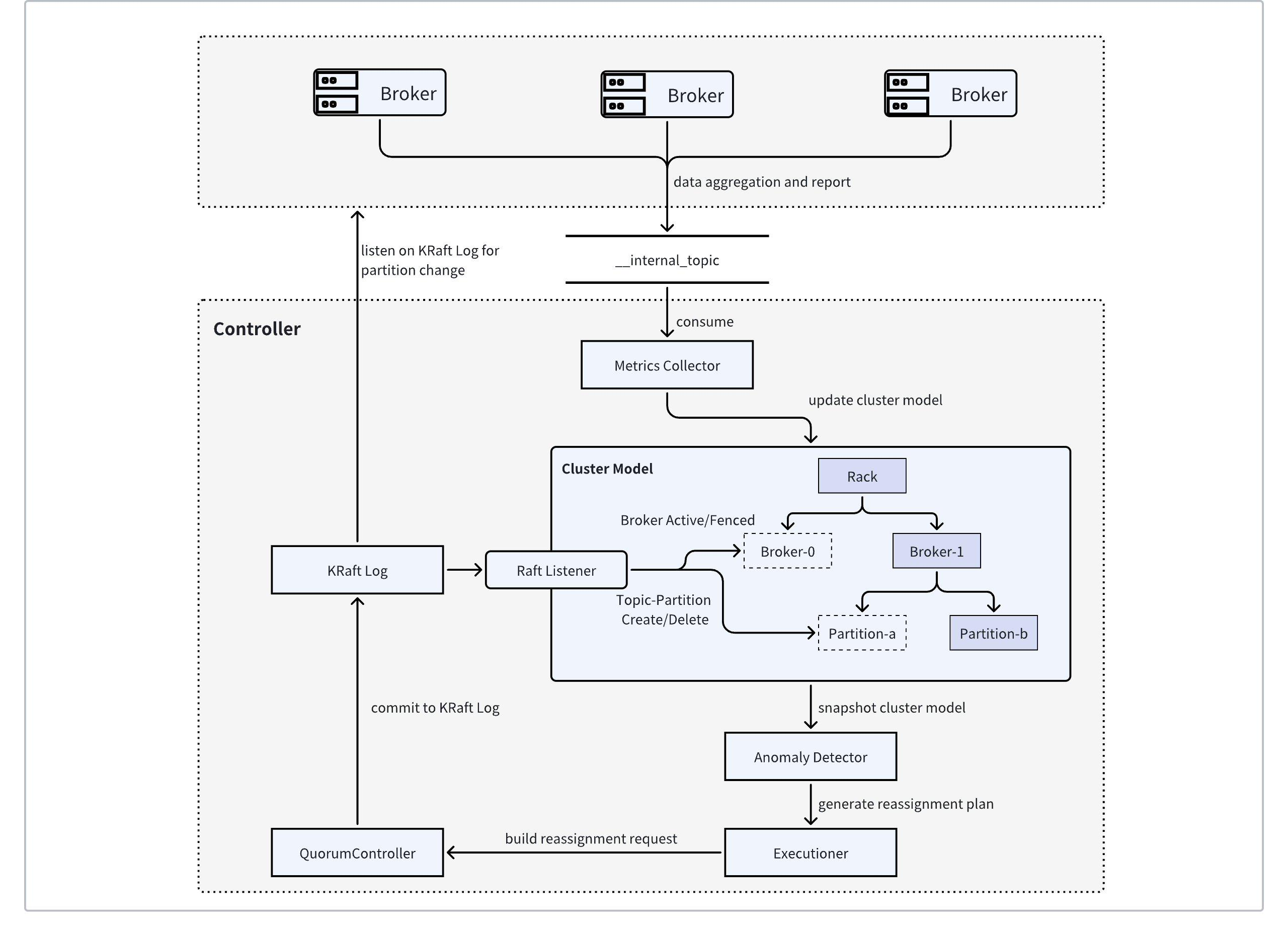
The above diagram illustrates the architecture of AutoMQ's built-in Auto Balancing component. This architecture collects cluster metrics and automatically formulates partition reassignment plans, continuously balancing the traffic across the entire cluster.
AutoMQ implements the Apache Kafka MetricsReporter interface, listening to all built-in metrics information of Apache Kafka. It periodically samples metrics of interest, such as network ingress and egress traffic, CPU utilization, etc. These pre-aggregated metrics are serialized into a Kafka message on the Broker side and sent to a designated internal topic.
The AutoMQ Controller maintains an in-memory cluster state model to describe the current cluster state, including Broker status, Broker resource capacity, and the traffic information of topic-partitions managed by each Broker. By listening to events in the KRaft log, the cluster state model can timely perceive the status changes of Brokers and topic-partitions and update the model accordingly to remain consistent with the actual cluster state.
Meanwhile, the metrics collector in the AutoMQ Controller consumes messages from the internal topic in real-time, deserializes the messages to parse specific metrics, and updates these metrics in the cluster state model, thereby constructing all the prerequisite information needed for data self-balancing.
AutoMQ Controller’s scheduling decision maker periodically takes snapshots of the cluster state model. Based on predefined “targets,” it identifies brokers with traffic that is too high or too low and attempts to reassign or exchange partitions to achieve self-balancing of traffic.
AutoMQ Data Self-Balancing Example
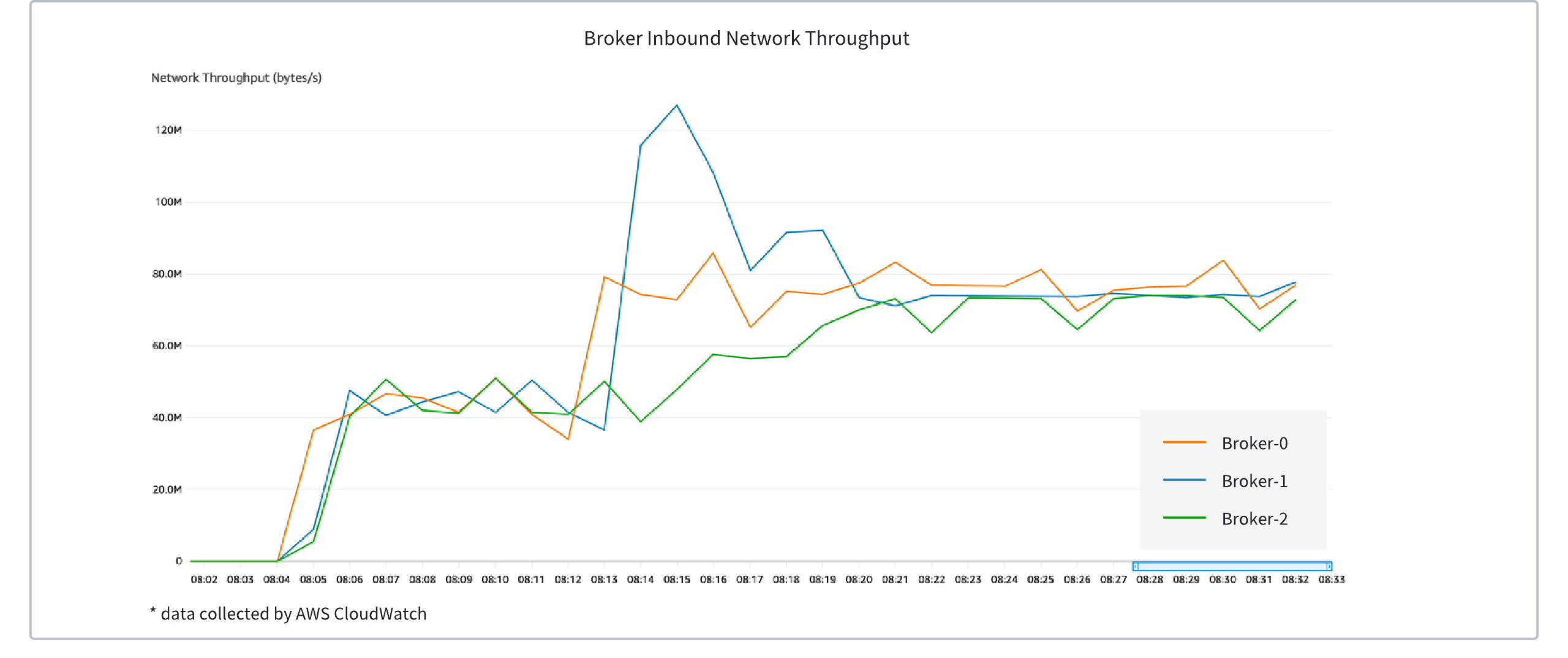
Taking a three-node AutoMQ cluster as an example, initially, each of the three nodes handles approximately 40MiB/s of write traffic evenly. In the second phase, Broker-0's traffic increases to about 80MiB/s, Broker-1’s traffic to about 120MiB/s, while Broker-2 maintains 40MiB/s. As shown in the above figure, automatic load balancing is triggered in the second phase, and the traffic of the three brokers gradually converges to a balanced range.
NOTE: In this scenario, to facilitate observation, the partition reassignment cooling time was artificially increased. With the default configuration, the traffic balancing time is about 1 minute.
Quick Experience
Refer to Example: Continuous Data Self-Balancing▸ to experience the continuous data self-balancing capability of AutoMQ.
References
[1]. LinkedIn’s open-source Cruise Control tool: https://github.com/linkedin/cruise-control