Ceph
前言
Ceph[1] 是一个开源的分布式对象,块和文件存储系统。该项目诞生于 2003 年,是塞奇・韦伊的博士论文的结果,然后在 2006 年在 LGPL 2.1 许可证发布。Ceph 已经与 Linux 内核 KVM 集成,并且默认包含在许多 GNU / Linux 发行版中。Ceph 的特点在于其同时提供了对象、块、文件系统的存储能力,可以适应各种不同的存储诉求。
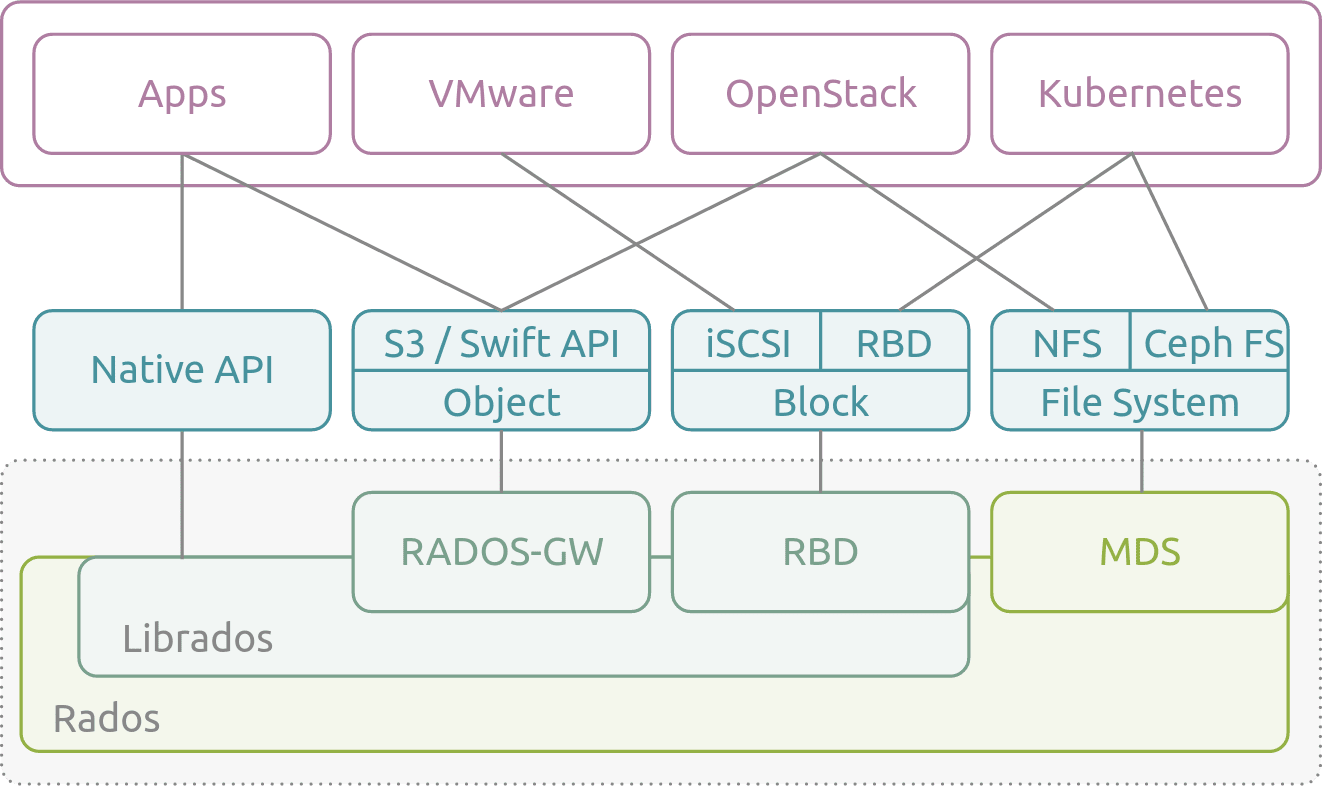
AutoMQ[2] 创新的共享存储架构需要同时使用低延迟的块设备以及低成本的对象存储,而 Ceph 同时支持 POSIX 和 S3 访问协议,因此对于 AutoMQ 具有很好的适配性。得益于 Ceph 对 S3 的兼容性以及其同时支持块存储、对象存储协议的特性,即使在私有数据中心,你仍然可以部署 AutoMQ 集群来获得一个与 Kafka 完全兼容,但是具备更好成本效益、极致弹性、个位数毫秒延迟的流系统。本文将指导你如何将 AutoMQ 集群部署在你私有数据中心的 Ceph 之上。
前置条件
一套可用的 Ceph 环境,可以参考官方文档安装 Ceph
参考官方文档,安装 Ceph 的 S3 兼容组件 RGW
准备 5 台主机用于部署 AutoMQ 集群。建议选择 2 核 16GB 内存的 Linux amd64 主机,并准备两个虚拟存储卷。示例如下:
角色 IP Node ID 系统卷 数据卷 CONTROLLER 192.168.0.1 0 EBS 20GB EBS 20GB CONTROLLER 192.168.0.2 1 EBS 20GB EBS 20GB CONTROLLER 192.168.0.3 2 EBS 20GB EBS 20GB BROKER 192.168.0.4 3 EBS 20GB EBS 20GB BROKER 192.168.0.5 4 EBS 20GB EBS 20GB Tips:
请确保这些机器处于相同的网段,可以互相通信
非生产环境也可以只部署 1 台 Controller,默认情况下该 Controller 也同时作为 Broker 角色
从 AutoMQ Github Releases 下载最新的正式二进制安装包,用于安装 AutoMQ。
为 Ceph 创建 Bucket
- 设置环境变量来配置 AWS CLI 需要的 Access Key 和 Secret Key。
export AWS_ACCESS_KEY_ID=X1J0E1EC3KZMQUZCVHED
export AWS_SECRET_ACCESS_KEY=Hihmu8nIDN1F7wshByig0dwQ235a0WAeUvAEiWSD- 使用 AWS CLI 创建 S3 存储桶。
aws s3api create-bucket --bucket automq-data --endpoint=http://127.0.0.1:80
aws s3api create-bucket --bucket automq-ops --endpoint=http://127.0.0.1:80为 Ceph 创建用户
radosgw-admin user create --uid="automq" --display-name="automq"
创建的用户默认拥有完整的 AutoMQ 所需权限。如需配置最小权限,请参考 CEPH 官方文档进行自定义设置。执行以上命令后的结果如下:
{
"user_id": "automq",
"display_name": "automq",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "automq",
"access_key": "X1J0E1EC3KZMQUZCVHED",
"secret_key": "Hihmu8nIDN1F7wshByig0dwQ235a0WAeUvAEiWSD"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
安装并启动 AutoMQ 集群
配置 S3URL
第 1 步:生成 S3 URL
AutoMQ 提供了 automq-kafka-admin.sh 工具,用于快速启动 AutoMQ。只需提供包含所需 S3 接入点和身份认证信息的 S3 URL,即可一键启动 AutoMQ,无需手动生成集群 ID 或进行存储格式化等操作。
### 命令行使用示例
bin/automq-kafka-admin.sh generate-s3-url \
--s3-access-key=xxx \
--s3-secret-key=yyy \
--s3-region=cn-northwest-1 \
--s3-endpoint=s3.cn-northwest-1.amazonaws.com.cn \
--s3-data-bucket=automq-data \
--s3-ops-bucket=automq-ops
当使用 Ceph 时,可以采用如下的配置来生成具体的 S3URL。
| 参数名 | 本例默认值 | 说明 |
|---|---|---|
| --s3-access-key | X1J0E1EC3KZMQUZCVHED | 创建 Ceph 用户后,记得按照实际情况进行替换 |
| --s3-secret-key | Hihmu8nIDN1F7wshByig0dwQ235a0WAeUvAEiWSD | 创建 Ceph 用户后,记得按照实际情况进行替换 |
| --s3-region | us-west-2 | 该参数在 Ceph 中无效,可以设置为任意值,例如 us-west-2 |
| --s3-endpoint | http://127.0.0.1:80 | 该参数是 Ceph 的 S3 兼容组件 RGW 对外服务的地址,如果有多台机器,推荐使用负载均衡器(SLB)来汇聚成一个 IP 地址。 |
| --s3-data-bucket | automq-data | - |
| --s3-ops-bucket | automq-ops | - |
输出结果
执行该命令后,将自动按以下阶段进行:
根据提供的 accessKey 和 secretKey 对 S3 基本功能进行探测,以验证 AutoMQ 和 S3 的兼容性。
根据身份信息,接入点信息生成 s3url。
根据 s3url 获取启动 AutoMQ 的命令示例。在命令中,将 --controller-list 和 --broker-list 替换为实际需要部署的 CONTROLLER 和 BROKER。
执行结果示例如下:
############ Ping s3 ########################
[ OK ] Write s3 object
[ OK ] Read s3 object
[ OK ] Delete s3 object
[ OK ] Write s3 object
[ OK ] Upload s3 multipart object
[ OK ] Read s3 multipart object
[ OK ] Delete s3 object
############ String of s3url ################
Your s3url is:
s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=xxx&s3-secret-key=yyy&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA
############ Usage of s3url ################
To start AutoMQ, generate the start commandline using s3url.
bin/automq-kafka-admin.sh generate-start-command \
--s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" \
--controller-list="192.168.0.1:9093;192.168.0.2:9093;192.168.0.3:9093" \
--broker-list="192.168.0.4:9092;192.168.0.5:9092"
TIPS: Please replace the controller-list and broker-list with your actual IP addresses.
第 2 步:生成启动命令列表
将上一步生成的命令中的 --controller-list 和 --broker-list 替换为你的主机信息,具体来说,将它们替换为环境准备中提到的 3 台 CONTROLLER 和 2 台 BROKER 的 IP 地址,并且使用默认的 9092 和 9093 端口。
bin/automq-kafka-admin.sh generate-start-command \
--s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" \
--controller-list="192.168.0.1:9093;192.168.0.2:9093;192.168.0.3:9093" \
--broker-list="192.168.0.4:9092;192.168.0.5:9092"
参数说明
| 参数名 | 必选 | 说明 |
|---|---|---|
| --s3-url | 是 | 由 bin/automq-kafka-admin.sh generate-s3-url 命令行工具生成,包含身份认证、集群 ID 等信息 |
| --controller-list | 是 | 至少需要有一个地址,用作 CONTROLLER 主机的 IP、端口列表。格式为 IP1:PORT1;IP2:PORT2;IP3:PORT3 |
| --broker-list | 是 | 至少需要有一个地址,用作 BROKER 主机的 IP、端口列表。格式为 IP1:PORT1;IP2:PORT2;IP3:PORT3 |
| --controller-only-mode | 否 | 决定 CONTROLLER 节点是否只承担 CONTROLLER 角色。默认为 false,即部署的 CONTROLLER 节点同时也作为 BROKER 角色。 |
输出结果
执行命令后,会生成用于启动 AutoMQ 的命令。
############ Start Commandline ##############
To start an AutoMQ Kafka server, please navigate to the directory where your AutoMQ tgz file is located and run the following command.
Before running the command, make sure that Java 17 is installed on your host. You can verify the Java version by executing 'java -version'.
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=0 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.1:9092,CONTROLLER://192.168.0.1:9093 --override advertised.listeners=PLAINTEXT://192.168.0.1:9092
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=1 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.2:9092,CONTROLLER://192.168.0.2:9093 --override advertised.listeners=PLAINTEXT://192.168.0.2:9092
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=2 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.3:9092,CONTROLLER://192.168.0.3:9093 --override advertised.listeners=PLAINTEXT://192.168.0.3:9092
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker --override node.id=3 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.4:9092 --override advertised.listeners=PLAINTEXT://192.168.0.4:9092
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker --override node.id=4 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.5:9092 --override advertised.listeners=PLAINTEXT://192.168.0.5:9092
TIPS: Start controllers first and then the brokers.
node.id 默认从 0 开始自动生成。
第 3 步:启动 AutoMQ
要启动集群,请在预先指定的 CONTROLLER 或 BROKER 主机上依次执行上一步命令中的命令列表。例如,在 192.168.0.1 上启动第一个 CONTROLLER 进程,执行生成的启动命令列表中的第一条命令模板。
bin/kafka-server-start.sh --s3-url="s3://s3.cn-northwest-1.amazonaws.com.cn?s3-access-key=XXX&s3-secret-key=YYY&s3-region=cn-northwest-1&s3-endpoint-protocol=https&s3-data-bucket=automq-data&s3-path-style=false&s3-ops-bucket=automq-ops&cluster-id=40ErA_nGQ_qNPDz0uodTEA" --override process.roles=broker,controller --override node.id=0 --override controller.quorum.voters=0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 --override listeners=PLAINTEXT://192.168.0.1:9092,CONTROLLER://192.168.0.1:9093 --override advertised.listeners=PLAINTEXT://192.168.0.1:9092
参数说明
使用启动命令时,未指定的参数将采用 Apache Kafka 的默认配置。对于 AutoMQ 新增的参数,将使用 AutoMQ 提供的默认值。要覆盖默认配置,可以在命令末尾添加额外的 --override key=value 参数来覆盖默认值。
| 参数名 | 必选 | 说明 |
|---|---|---|
| s3-url | 是 | 由 bin/automq-kafka-admin.sh generate-s3-url 命令行工具生成,包含身份认证、集群 ID 等信息 |
| process.roles | 是 | 可选项为 CONTROLLER 或 BROKER。如果一台主机同时为 CONTROLLER 和 BROKER,则配置值为 CONTROLLER,BROKER。 |
| node.id | 是 | 整数,用于唯一标识 Kafka 集群中的 BROKER 或 CONTROLLER,在集群内部必须保持唯一性。 |
| controller.quorum.voters | 是 | 参与 KRAFT 选举的主机信息,包含 nodeid、ip 和 port 信息,例如:0@192.168.0.1:9093,1@192.168.0.2:9093,2@192.168.0.3:9093 |
| listeners | 是 | 监听的 IP 和端口 |
| advertised.listeners | 是 | BROKER 为 Client 提供的接入地址。 |
| log.dirs | 否 | 存放 KRAFT、BROKER 元数据的目录。 |
| s3.wal.path | 否 | 在生产环境中,建议将 AutoMQ WAL 数据存放在一个独立挂载的新数据卷裸设备上。这样可以获得更好的性能表现,因为 AutoMQ 支持将数据写入裸设备,从而降低延迟。请确保配置正确的路径以存储 WAL 数据。 |
| autobalancer.controller.enable | 否 | 默认值为 false,不启用流量重平衡。自动开启流量重平衡后,AutoMQ 的 auto balancer 组件会自动迁移分区,以确保整体流量是均衡的。 |
Tips: 若需启用持续流量重平衡或运行 Example: Self-Balancing When Cluster Nodes Change,建议在启动时为 Controller 明确指定参数 --override autobalancer.controller.enable=true。
后台运行
如果需要以后台模式运行,请在命令末尾添加以下代码:
command > /dev/null 2>&1 &
准备裸设备数据卷
AutoMQ 使用裸设备作为 WAL 的数据卷,用于提高写入 WAL 的效率。在 Ceph 上可以按照如下方式准备裸设备
参考 Ceph 官方文档中关于在 Linux 主机上挂载裸设备的指引准备裸设备
将裸设备路径配置为/dev/vdb。
数据卷路径
使用 Linux 的 lsblk 命令可查看本地数据卷,未分区的块设备即为数据卷。在以下示例中,vdb 是未分区的裸块设备。
vda 253:0 0 20G 0 disk
├─vda1 253:1 0 2M 0 part
├─vda2 253:2 0 200M 0 part /boot/efi
└─vda3 253:3 0 19.8G 0 part /
vdb 253:16 0 20G 0 disk
默认情况下,AutoMQ 存储元数据和 WAL 数据的位置是在 /tmp 目录下。然而,值得注意的是,如果 /tmp 目录是挂载在 tmpfs 上的,则不适合用于生产环境。
为了更适合生产或正式测试环境,建议按照以下方式修改配置:将元数据目录 log.dirs 和 WAL 数据目录 s3.wal.path(写数据盘的裸设备)指定到裸设备的路径。
bin/kafka-server-start.sh ...\
--override s3.telemetry.metrics.exporter.type=prometheus \
--override s3.metrics.exporter.prom.host=0.0.0.0 \
--override s3.metrics.exporter.prom.port=9090 \
--override log.dirs=/root/kraft-logs \
--override s3.wal.path=/dev/vdb \
> /dev/null 2>&1 &
Tips: /dev/vdb 是我们通过 Ceph 准备的裸设备路径
至此,你已经完成了基于 Ceph 的 AutoMQ 集群部署,拥有了一个低成本、低延迟、秒级弹性的 Kafka 集群了。如果你需要进一步体验 AutoMQ 的秒级分区迁移、持续自平衡等特性,可以参考官方示例。
参考资料
[1] Ceph: https://ceph.io/en/
[2] What is ceph: https://ubuntu.com/ceph/what-is-ceph