CubeFS
前言
CubeFS [1] 是新一代云原生存储产品,目前是云原生计算基金会(CNCF)托管的孵化阶段开源项目, 兼容 S3、POSIX、HDFS 等多种访问协议,支持多副本与纠删码两种存储引擎,为用户提供多租户、 多 AZ 部署以及跨区域复制等多种特性,广泛应用于大数据、AI、容器平台、数据库、中间件存算分离、数据共享以及数据保护等场景。
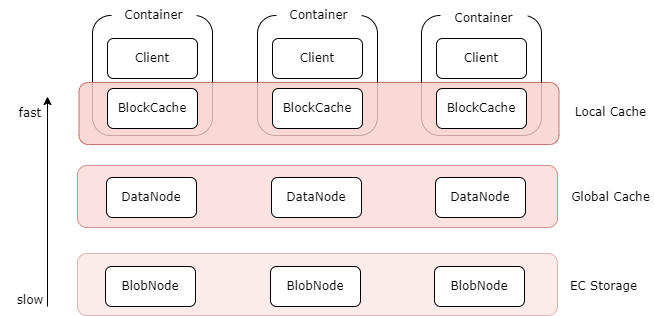
AutoMQ 创新的共享存储架构需要低成本的对象存储,而 CubeFS 支持 S3 兼容接口,其中 ObjectNode 提供兼容 S3 的对象存储接口来操作 CubeFS 中的文件,因此可以使用 S3Browser、S3Cmd 等开源工具或者原生的 Amazon S3 SDK 操作 CubeFS 中的文件。因此对于 AutoMQ 具有很好的适配性。因此你可以部署 AutoMQ 集群来获得一个与 Kafka 完全兼容,但是具备更好成本效益、极致弹性、个位数毫秒延迟的流系统。
本文将介绍如何将 AutoMQ 集群部署到您私有数据中心的 CubeFS 上。
快速开始
准备 CubeFS 集群
- 一个可用的 CubeFS 环境。如果您还没有 CubeFS 环境,可以参考官方文档进行依赖配置 [3] 以及搭建 CubeFS 基础集群 [4] 。
CubeFS 支持使用脚本一键部署基础集群,基础集群包含组件 Master 、 MetaNode 、 DataNode ,同时可额外选择启动 client 和 ObjectNode 。 步骤如下:
cd ./cubefs
# 编译
make
# 生成配置文件并启动基础集群 请修改 bond0 为你自己的网卡名。
sh ./shell/deploy.sh /home/data bond0
CubeFS 默认的安装包下的 build/bin 目录提供了一系列管理集群的命令行工具。本文中也将使用这些命令行工具做一些额外配置。通过 CubeFS 命令行工具查看集群状态,验证是否搭建成功:
# 执行命令
./build/bin/cfs-cli cluster info
# 结果输出
[Cluster]
Cluster name : cfs_dev
Master leader : 172.16.1.101:17010
Master-1 : 172.16.1.101:17010
Master-2 : 172.16.1.102:17010
Master-3 : 172.16.1.103:17010
Auto allocate : Enabled
MetaNode count (active/total) : 4/4
MetaNode used : 0 GB
MetaNode available : 21 GB
MetaNode total : 21 GB
DataNode count (active/total) : 4/4
DataNode used : 44 GB
DataNode available : 191 GB
DataNode total : 235 GB
Volume count : 2
...
注意:这里的 CubeFS 集群的 master 节点的 ip 和端口将在接下来的对象网关配置中使用。
启用对象网关
为了让 CubeFS 支持对象存储协议,您需要开启对象网关 [5]。对象网关的作用在于,它提供了与 S3 兼容的对象存储接口,这使得 CubeFS 不仅能够支持传统的 POSIX 文件系统接口,还能够支持 S3 兼容的对象存储接口。通过这种方式,CubeFS 能够融合这两种通用类型接口的优势,进而为用户提供更为灵活的数据存储及访问方案。具体而言,开启对象网关后,用户便可以利用原生的 Amazon S3 SDK 来操作存储在 CubeFS 中的文件,从而享受到对象存储的便利性。
为了更方便的启动对象网关,你可以直接在 CubeFS 的根目录下执行下面这个命令以启动对象网关,这将启动一个默认监听端口为 17410 的对象网关服务:
sh ./shell/deploy_object.sh /home/data
你将得到如下结果,说明网关已经成功启动:
[output]
mkdir -p /home/data/object/logs
start checking whether the volume exists
begin create volume 'objtest'
Create volume success.
begin start objectnode service
start objectnode service success
创建 CubeFS 用户
- 创建 CubeFS 用户,并查询得到
AccessKey以及Secret AccessKey等信息。
可以参考用户管理文档 [6] 进行创建并查询对应用户的信息。
CubeFS 支持多种创建方式,比如可以通过 AWS SDK [7] 的方式进行创建或者 HTTP 请求的方式创建,这里我们将演示通过 HTTP 请求的方式进行创建:
- 指定用户 id,密码以及 type,并请求创建接口:
curl -H "Content-Type:application/json" -X POST --data '{"id":"automq","pwd":"12345","type":2}' "http://172.16.1.101:17010/user/create"
- 通过用户 ID 查询用户信息:
curl -v "http://172.16.1.101:17010/user/info?user=automq" | python -m json.tool
- 响应示例。这里我们可以得到该用户的 AK 和 SK,用作后续操作对象存储的凭证。
{
"code": 0,
"msg": "success",
"data": {
"user_id": "automq",
"access_key": "Ys3SYUdusPxGfS7J",
"secret_key": "HdhEnzEgo63naqx8opUhXMgiBOdCKmmf",
"policy": {
"own_vols": [
],
"authorized_vols": {
}
},
"user_type": 2,
"create_time": "2024-07-17 12:12:59",
"description": "",
"EMPTY": false
}
}
使用 S3 接口创建 Bucket
使用 aws cli 工具在 CubeFS 上创建需要的 bucket 以用于 AutoMQ 的集群部署。
拿到用户的 key 等信息,通过 aws configure 进行配置,并使用 aws cli 工具进行 bucket 的创建。
aws s3api create-bucket --bucket automq-data --endpoint=http://127.0.0.1:17410
aws s3api create-bucket --bucket automq-ops --endpoint=http://127.0.0.1:17410
使用命令查看已经有的 bucket
aws s3 ls --endpoint=http://127.0.0.1:17410
安装并启动 AutoMQ 集群
可参考 AutoMQ 官网文档进行 AutoMQ 集群的部署:在 Linux 主机上以集群方式部署 | AutoMQ [8]
至此,你已经完成了基于 CubeFS 的 AutoMQ 集群部署,拥有了一个低成本、低延迟、秒级弹性的 Kafka 集群了。如果你需要进一步体验 AutoMQ 的秒级分区迁移、持续自平衡等特性,可以参考官方示例 [9]。
参考资料
[1] CubeFS: https://www.cubefs.io
[2] CubeFS 的多级缓存: https://www.cubefs.io/docs/master/overview/introduction.html
[3] 依赖配置: CubeFS | A Cloud Native Distributed Storage System
[4] CubeFS 单机部署: www.cubefs.io
[5] 对象网关: https://www.cubefs.io/zh/docs/master/design/objectnode.html
[6] CubeFS 用户管理文档: CubeFS | A Cloud Native Distributed Storage System
[7] CubeFS AWS SDK: https://www.cubefs.io/zh/docs/master/user-guide/objectnode.html
[8] 在 Linux 主机上以集群方式部署 | AutoMQ : https://docs.automq.com/zh/automq/getting-started/cluster-deployment-on-linux