CubeFS
Preface
CubeFS [1] is a next-generation cloud-native storage product, currently an incubating open-source project hosted by the Cloud Native Computing Foundation (CNCF). It is compatible with multiple access protocols such as S3, POSIX, and HDFS, supporting both multi-replica and erasure coding storage engines. It provides users with features such as multi-tenancy, multi-AZ deployment, and cross-region replication. CubeFS is widely used in scenarios like big data, AI, container platforms, databases, middleware, compute-storage separation, data sharing, and data protection.
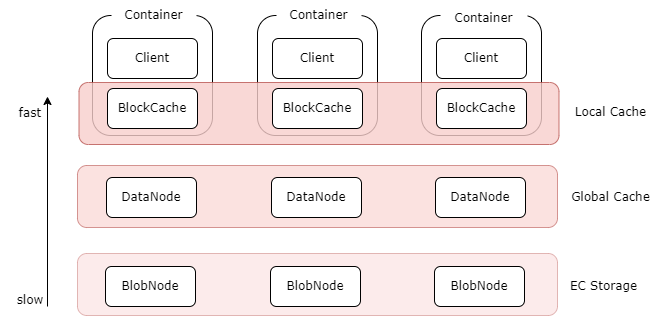
AutoMQ's innovative shared storage architecture requires low-cost object storage. CubeFS supports S3-compatible interfaces, with ObjectNode providing an S3-compatible object storage interface to operate files within CubeFS. Therefore, you can use open-source tools like S3Browser, S3Cmd, or the native Amazon S3 SDK to manage files in CubeFS, making it highly compatible with AutoMQ. You can thus deploy an AutoMQ cluster to obtain a fully Kafka-compatible streaming system that offers better cost efficiency, extreme scalability, and single-digit millisecond latency.
This article will introduce how to deploy an AutoMQ cluster onto CubeFS in your private data center.
Quick Start
Prepare CubeFS Cluster
- A working CubeFS environment. If you do not have a CubeFS environment, please refer to the official documentation for dependency configuration [3] and setting up the CubeFS basic cluster [4].
CubeFS supports one-click deployment of a basic cluster using scripts. The basic cluster includes components such as Master, MetaNode, and DataNode. You can also optionally start client and ObjectNode. The steps are as follows:
cd ./cubefs
# Compile
make
# Generate the Configuration File and Start the Basic Cluster. Please Replace Bond0 with Your Own Network Interface Name.
sh ./shell/deploy.sh /home/data bond0
The build/bin directory under the default CubeFS installation package provides a series of command-line tools for managing the cluster. In this article, these command-line tools will also be used for some additional configuration. Use CubeFS command-line tools to check the cluster status and verify if the setup was successful:
# Execute the Command
./build/bin/cfs-cli cluster info
# Result Output
[Cluster]
Cluster name : cfs_dev
Master leader : 172.16.1.101:17010
Master-1 : 172.16.1.101:17010
Master-2 : 172.16.1.102:17010
Master-3 : 172.16.1.103:17010
Auto allocate : Enabled
MetaNode count (active/total) : 4/4
MetaNode used : 0 GB
MetaNode available : 21 GB
MetaNode total : 21 GB
DataNode count (active/total) : 4/4
DataNode used : 44 GB
DataNode available : 191 GB
DataNode total : 235 GB
Volume count : 2
...
Note: The IP and port of the master node of the CubeFS cluster will be used in the following object gateway configuration.
Enable the Object Gateway
To enable CubeFS to support the object storage protocol, you need to activate the object gateway [5]. The purpose of the object gateway is to provide an S3-compatible object storage interface. This allows CubeFS to support both traditional POSIX file system interfaces and S3-compatible object storage interfaces. By doing so, CubeFS can leverage the advantages of both general-purpose interfaces, providing users with a more flexible data storage and access solution. Specifically, after enabling the object gateway, users can use the native Amazon S3 SDK to operate files stored in CubeFS, thereby enjoying the convenience of object storage.
To facilitate the startup of the object gateway, you can directly execute the following command in the root directory of CubeFS to start the object gateway, which will start an object gateway service listening on the default port 17410:
sh ./shell/deploy_object.sh /home/data
You will get the following result, indicating that the gateway has been successfully started:
[output]
mkdir -p /home/data/object/logs
start checking whether the volume exists
begin create volume 'objtest'
Create volume success.
begin start objectnode service
start objectnode service success
Create CubeFS User
- Create a CubeFS user and retrieve the
AccessKeyandSecret AccessKeyinformation.
Refer to the user management documentation [6] for creating and querying the corresponding user information.
CubeFS supports multiple creation methods. For instance, you can create via the AWS SDK [7] or using HTTP requests. Here, we will demonstrate the creation method via HTTP requests:
- Specify the user id, password, and type, and request the creation interface:
curl -H "Content-Type:application/json" -X POST --data '{"id":"automq","pwd":"12345","type":2}' "http://172.16.1.101:17010/user/create"
- Query user information by user ID:
curl -v "http://172.16.1.101:17010/user/info?user=automq" | python -m json.tool
- Here is the response example. Here, we can obtain the user's AK and SK, which will be used as credentials for subsequent object storage operations.
{
"code": 0,
"msg": "success",
"data": {
"user_id": "automq",
"access_key": "Ys3SYUdusPxGfS7J",
"secret_key": "HdhEnzEgo63naqx8opUhXMgiBOdCKmmf",
"policy": {
"own_vols": [
],
"authorized_vols": {
}
},
"user_type": 2,
"create_time": "2024-07-17 12:12:59",
"description": "",
"EMPTY": false
}
}
Create a Bucket Using the S3 Interface.
Use the aws cli tool to create the necessary bucket on CubeFS for AutoMQ cluster deployment.
Obtain the user's key and other information, configure it using aws configure, and then use the aws cli tool to create the bucket.
aws s3api create-bucket --bucket automq-data --endpoint=http://127.0.0.1:17410
aws s3api create-bucket --bucket automq-ops --endpoint=http://127.0.0.1:17410
Use commands to view existing buckets.
aws s3 ls --endpoint=http://127.0.0.1:17410
Install and Start the AutoMQ Cluster.
Refer to the official AutoMQ documentation for deploying the AutoMQ cluster: Cluster Deployment on Linux | AutoMQ [8]
At this point, you have completed the AutoMQ cluster deployment on CubeFS, providing a low-cost, low-latency, and highly elastic Kafka cluster. If you want to further experience features such as second-level partition reassignment and self-balancing, you can refer to the official example [9].
References
[1] CubeFS: https://www.cubefs.io
[2] CubeFS Multi-Level Caching: https://www.cubefs.io/docs/master/overview/introduction.html
[3] Dependency Configuration: CubeFS | A Cloud Native Distributed Storage System
[4] CubeFS Single-node Deployment: www.cubefs.io
[5] Object Gateway: https://www.cubefs.io/docs/master/design/objectnode.html
[6] CubeFS User Management Documentation: CubeFS | A Cloud Native Distributed Storage System
[7] CubeFS AWS SDK: https://www.cubefs.io/docs/master/user-guide/objectnode.html
[8] Cluster Deployment on Linux | AutoMQ: https://docs.automq.com/automq/getting-started/cluster-deployment-on-linux
[9] Official Example: https://docs.automq.com/automq/getting-started